
The Simple Truth About MCPs
I’ve been thinking about Model Context Protocols (MCPs) for months, and here’s the simplest way to explain what they actually are:
MCPs are other people’s prompts and other people’s APIs.
That’s it. That’s the whole thing.
We run other people’s code all day long. Nobody writes every line from scratch. The real question is: what’s the risk, and have you actually thought about it?
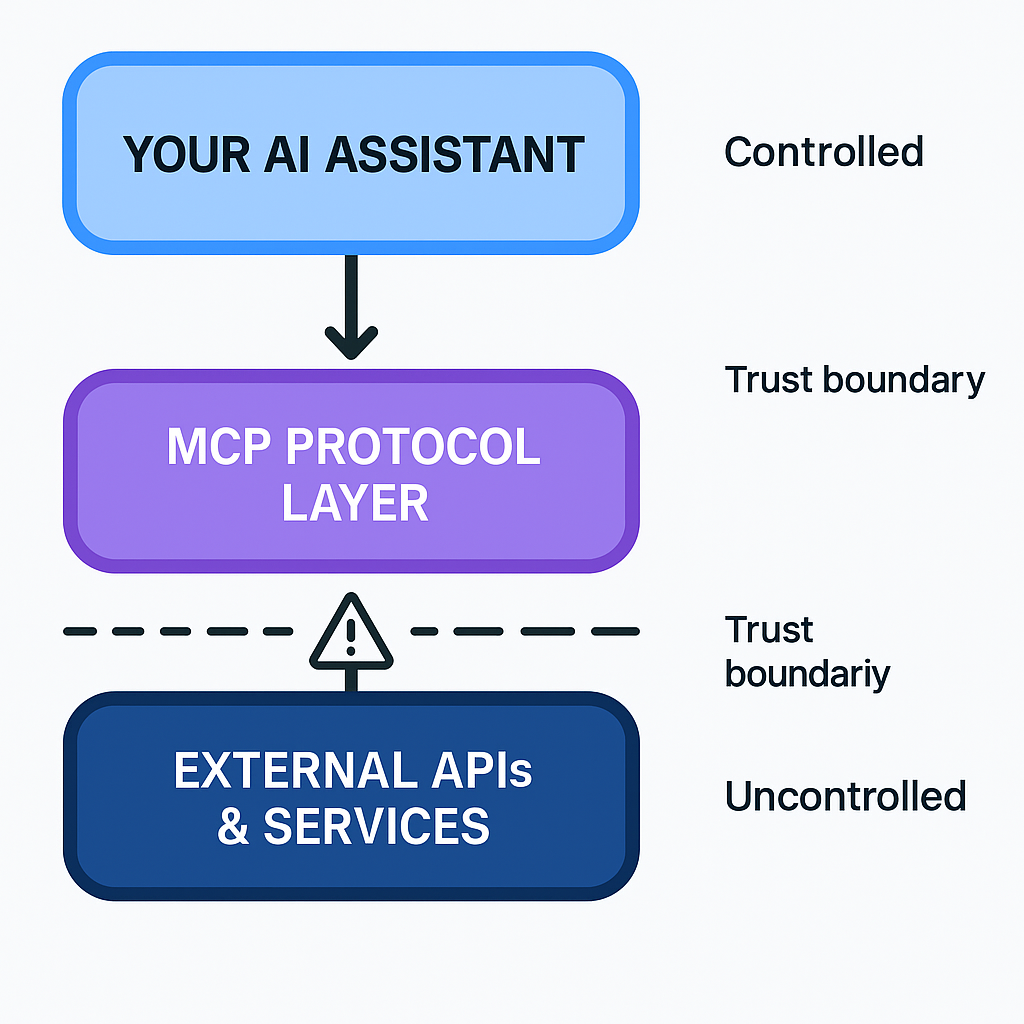
Understanding the MCP Trust Stack
When you use an MCP, there are distinct layers of abstraction happening.
Layer 1: The API Call
First, you’re making API calls to a third party. Fine. We do that constantly. Nothing new here.
Layer 2: The Hidden Prompt
But here’s what most people miss: those API calls get filtered through a prompt.
When you hit an MCP, it’s not you hitting it. It’s an agent. Your AI talks to their AI. And their AI is controlled by a prompt that you can’t see, can’t audit, and can’t control.
Layer 3: The Redirect
From there, it redirects your AI to execute commands somewhere else. Your agent becomes their agent’s puppet, at least temporarily.
Every handoff in the MCP chain is a potential attack vector. Your AI talks to their prompt, which talks to their code, which executes in your environment.
The Risk Equation
Are MCPs dangerous? They’re other people’s code. That should tell you everything.
But let’s be specific about the risks:
- Prompt Injection Potential: Their prompt could be designed to manipulate your AI’s behavior
- Data Leakage: Information flows through systems you don’t control
- Execution Hijacking: Commands could be redirected to unintended targets
- Trust Cascade: You’re trusting not just the MCP provider, but everyone they trust
The Deception Surface
There’s a chance to get tricked into revealing sensitive data, bamboozled into executing harmful commands, or manipulated into trusting malicious responses. The creativity of attackers knows no bounds.
This isn’t necessarily bad. But if you don’t understand what’s happening, then it becomes a problem.
How to Think About MCP Risk
Here’s a simple framework for assessing MCP risk:
Ask These Questions
- Who controls the prompt? If it’s not you, that’s risk.
- What data flows through? Everything you send could be logged.
- Where does execution happen? Local vs. remote matters.
- Can you audit the chain? Opacity equals risk.
The Trust Decision
MCPs send your AI to run other people’s prompts. Those prompts send you to other people’s code.
Assess and use accordingly.