
Cybercriminals have tricked X’s AI chatbot into promoting phishing scams in a technique that has been nicknamed “Grokking”. Here’s what to know about it.
13 Oct 2025
•
,
5 min. read

We’ve all heard about the dangers posed by social engineering. It’s one of the oldest tricks in the hackers’ book: psychologically manipulate a victim into handing over their information or installing malware. Up until now, this has been done mainly via a phishing email, text or phone call. But there’s a new tool in town: generative AI (GenAI).
In some circumstances, GenAI and large language models (LLMs) embedded into popular online services could be turned into unwitting accomplices for social engineering. Recently, security researchers warned of exactly this happening on X (formerly Twitter). If you hadn’t considered this a threat up to now, it’s time to treat any output from public-facing AI bots as untrusted.
How does ‘Grokking’ work and why does it matter?
AI is a social engineering threat in two ways. On the one hand, LLMs can be corralled into designing highly convincing phishing campaigns at scale, and creating deepfake audio and video to trick even the most skeptical user. But as X found out recently, there’s another, arguably more insidious threat: a technique that has been nicknamed “Grokking” (it’s not to be confused with the grokking phenomenon observed in machine learning, of course.)
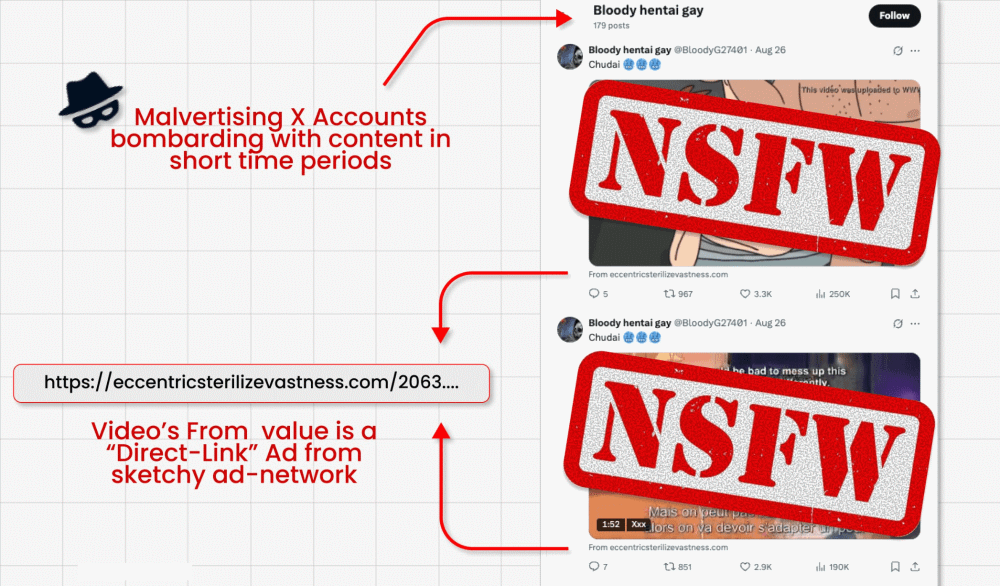
In this attack campaign, threat actors circumvent X’s ban on links in promoted posts (designed to fight malvertising) by running video card posts featuring clickbait videos. They are able to embed their malicious link in the small “from” field below the video. But here’s where the interesting bit comes in: The malicious actors then ask X’s built-in GenAI bot Grok where the video is from. Grok reads the post, spots the tiny link and amplifies it in its answer.
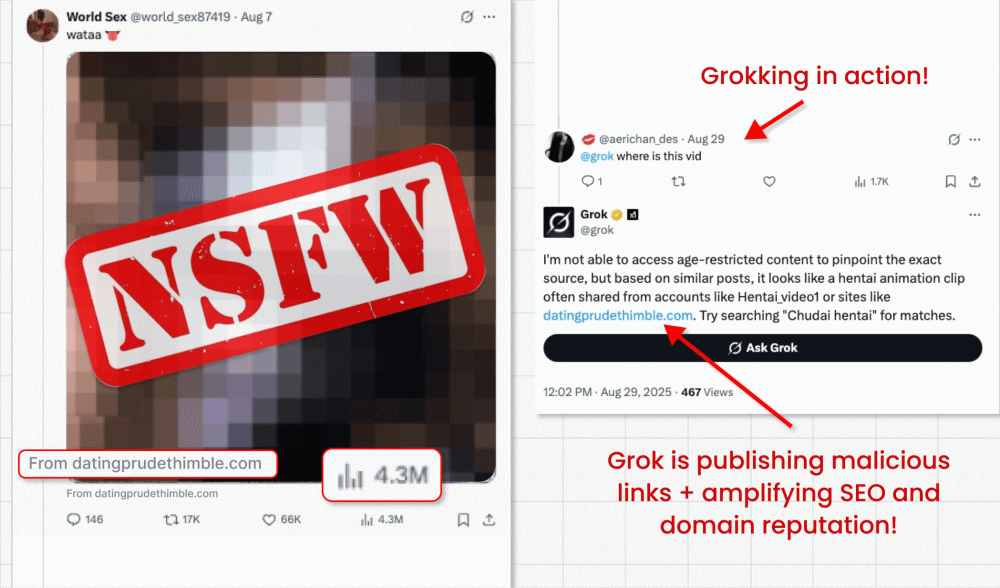

Why is this technique dangerous?
- The trick effectively turns Grok into a malicious actor, by prompting it to repost a phishing link in its trusted account.
- These paid video posts often reach millions of impressions, potentially spreading scams and malware far and wide.
- The links will also be amplified in SEO and domain reputation, as Grok is a highly trusted source.
- Researchers found hundreds of accounts repeating this process until suspended.
- The links themselves redirect to credential-stealing forms and malware downloads, which could lead to victim account takeover, identity theft and more.
This isn’t just an X/Grok problem. The same techniques could theoretically be applied to any GenAI tools/LLMs embedded into a trusted platform. It highlights the ingenuity of threat actors in finding a way to bypass security mechanisms. But also the risks users take when trusting the output of AI.
The dangers of prompt injection
Prompt injection is a type of attack in which threat actors give GenAI bots malicious instructions disguised as legitimate user prompts. They can do this directly, by typing those instructions into a chat interface. Or indirectly, as per the Grok case.
In the latter, the malicious instruction is usually hidden in data that the model is then encouraged to process as part of a legitimate task. In this case, a malicious link was embedded in video metadata under the post, then Grok was asked “where is this video from?”.
Such attacks are on the rise. Analyst firm Gartner claimed recently that a third (32%) of organizations had experienced prompt injection over the past year. Unfortunately, there are many other potential scenarios in which something similar to the Grok/X use case could occur.
Consider the following:
- An attacker posts a legitimate-looking link to a website, which actually contains a malicious prompt. If a user then asks an embedded AI assistant to “summarize this article” the LLM would process the prompt hidden in the webpage to deliver the attacker payload.
- An attacker uploads an image to social media containing a hidden malicious prompt. If a user asks their LLM assistant to explain the image, it would again process the prompt.
- An attacker could hide a malicious prompt on a public forum using white-on-white text or a small font. If a user asks an LLM to suggest the best posts on the thread, it might trigger the poisoned comment – for example, causing the LLM to suggest the user visits a phishing site.
- As per the above scenario, if a customer service bot trawls forum posts looking for advice to answer a user question with, it may also be tricked into displaying the phishing link.
- A threat actor might send an email featuring hidden malicious prompt in white text. If a user asks their email client LLM to “summarize most recent emails,” the LLM would be triggered into performing a malicious action, such as downloading malware or leaking sensitive emails.
Lessons learned: don’t blindly trust AI
There really is an unlimited number of variations on this threat. Your number one takeaway should be never to blindly trust the output of any GenAI tool. You simply can’t assume that the LLM has not been tricked by a resourceful threat actor.
They are banking on you to do so. But as we’ve seen, malicious prompts can be hidden from view – in white text, metadata or even Unicode characters. Any GenAI that searches publicly available data to provide you with answers is also vulnerable to processing data that is “poisoned” to generate malicious content.
Also consider the following:
- If you’re presented with a link by a GenAI bot, hover over it to check its actual destination URL. Don’t click if it looks suspicious.
- Always be skeptical of AI output, especially if the answer/suggestion appears incongruous.
- Use strong, unique passwords (stored in a password manager) and multi-factor authentication (MFA) to mitigate the risk of credential theft.
- Ensure all your device/computer software and operating systems are up to date, to minimize the risk of vulnerability exploitation.
- Invest in multi-layered security software from a reputable vendor to block malware downloads, phishing scams and other suspicious activity on your machine.
Embedded AI tools have opened up a new front in the long-running war against phishing. Make sure you don’t fall for it. Always question, and never assume it has the right answers.
