
South Korean researchers (Youngjin Jin, Eugene Jang, Jian Cui, Jin-Woo Chung, Yongjae Lee, Seungwon Shin) at KAIST (Korea Advanced Institute of Science & Technology) developed DarkBERT.
This AI model ventured into the depths of the dark web, an anonymous and concealed part of the internet, to index and gathered information from its shadiest domains.
The “Dark Web” is an inaccessible and concealed segment of the internet, known for its anonymous websites and illicit marketplaces that facilitate activities like illegal trade, data breaches, and cybercrime.
DarkBERT on Dark Web
The ‘Dark Web’ relies on sophisticated methods to hide user identities, making it challenging to track their online activities. Tor is the favored software for accessing this section, used by millions daily.

DarkBERT, built on the RoBERTa architecture, has experienced a resurgence as researchers found untapped performance potential due to its initial undertraining, leading to enhanced efficiency beyond its 2019 capabilities.
Researchers are exploring how large language models (LLMs) like ChatGPT can combat cybercrime by harnessing the power of artificial intelligence to fight fire with fire.
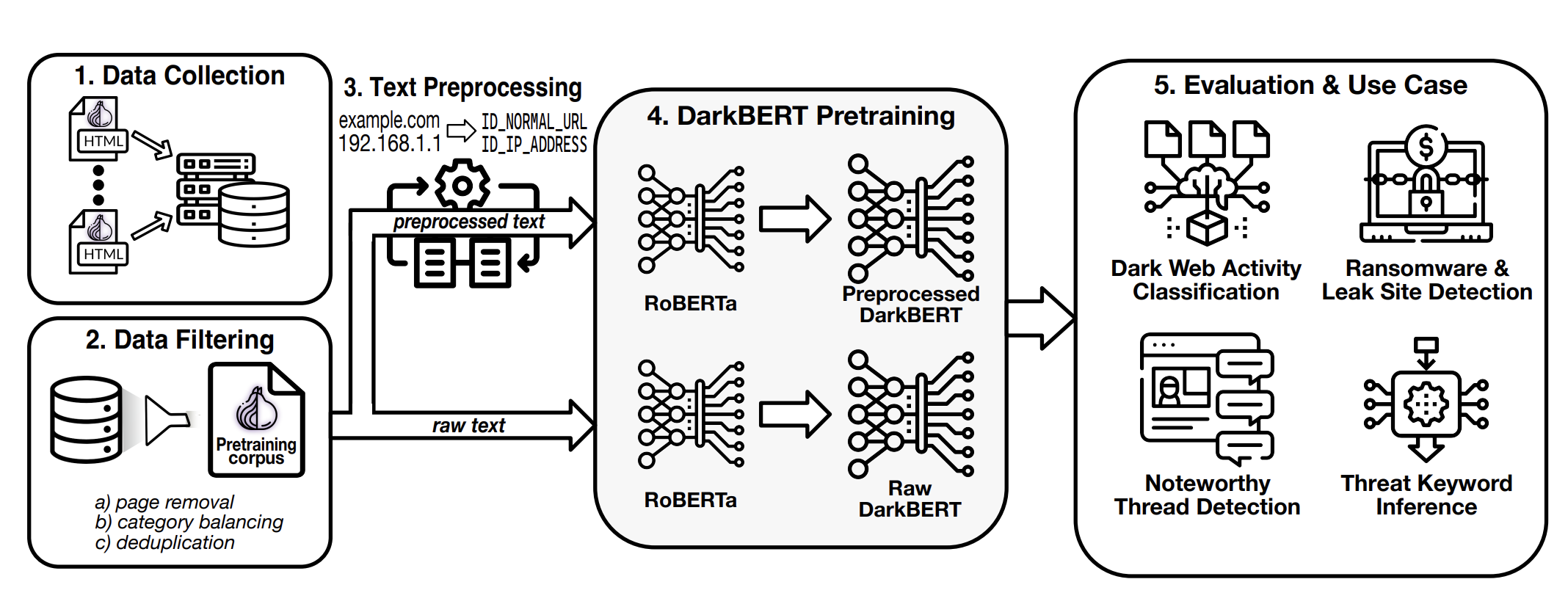
With this aim in mind, the researchers have unveiled their findings in a publication titled “DarkBERT: Illuminating the Language Model’s Exploration of the Dark Web.” They gathered unprocessed information by integrating their model with the Tor network, forming a comprehensive database.
The assessment findings of the researchers demonstrate the superiority of the classification model based on DarkBERT compared to established pre-trained language models.
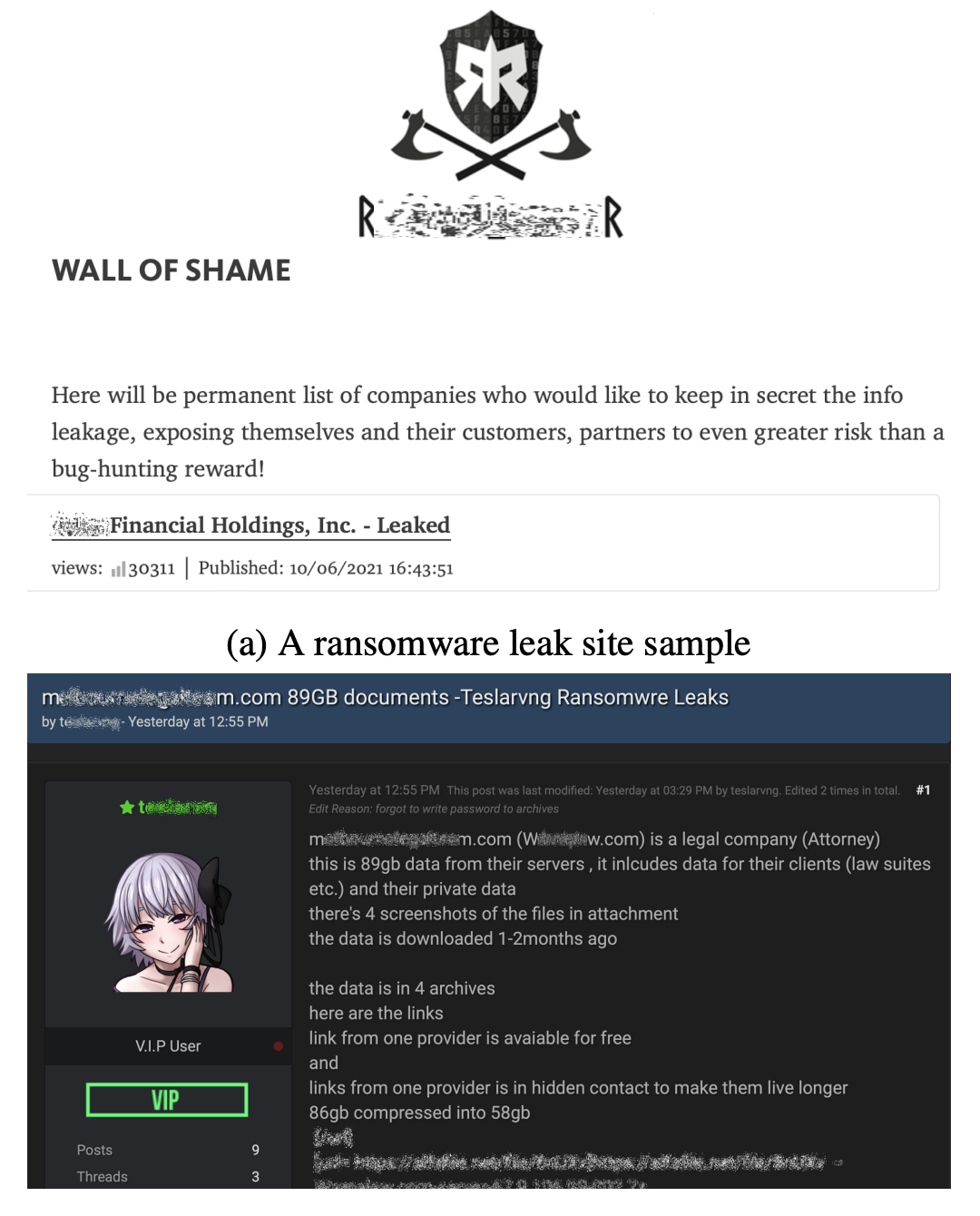
The team proposes that DarkBERT holds potential for diverse cybersecurity applications, including identifying websites involved in the sale of ransomware or the unauthorized disclosure of sensitive information.
Additionally, DarkBERT can traverse the various dark web forums, which undergo daily updates, enabling vigilant monitoring for illicit information exchanges.
Use Cases in the Cybersecurity Domain
Here below, we have mentioned all the use cases in the Cybersecurity Domain:-
Ethical Considerations & Limitations
Here below, we have mentioned all the Ethical Considerations:-
- Crawling the Dark Web
- Sensitive Information Masking
- Annotator Ethics
- Use of Public Dark Web Datasets
Here below, we have mentioned all the Limitations:-
- Limited Usage for Non-English Tasks
- Dependence on Task-Specific Data
By crawling the Dark Web using the Tor network’s anonymizing firewall and filtering the collected data with techniques like deduplication, category balancing, and data pre-processing, the researchers created a Dark Web database, which was then used to train DarkBERT.
Although DarkBERT, like other large language models (LLMs), is not a finished product, ongoing training and refinement can enhance its performance, and its specific applications and potential insights are yet to be fully explored.
DarkBERT demonstrates the potential for future research in the Dark Web field and the cybersecurity industry. It plans to enhance its performance by utilizing newer architectures, expanding data collection, and developing a multilingual language model specific to the Dark Web domain.
Common Security Challenges Facing CISOs? – Download Free CISO’s Guide







