We frequently hear that we have a data scarcity problem in AI. And when it comes to unique, Tolstoy-level literature and the like, that could be true.
But in the business world I think we have the exact opposite problem.
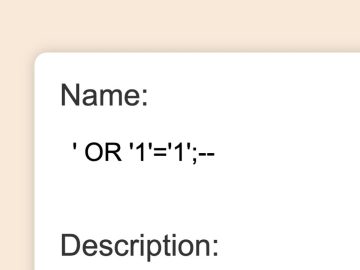
What we actually have is a, “There’s absolutely nobody to look at 99.999% of our data” problem.
According to IDC’s Data Age 2025 report, we’re generating 149 zettabytes of data annually. That’s 149 trillion gigabytes. Every single year.
Here’s what’s actually happening to it:
Surveillance and security:
IoT and industrial sensors:
Enterprise operations:
As far as totals, we’re talking about 149 zettabytes generated globally each year, only 12-15% is ever examined by humans or AI (IDC Data Age 2025). That’s roughly 20 zettabytes.
As far as I’m concerned, yes, there might not be new high-quality literature being generated, which I suppose is a problem. Maybe we’re running out of that, and I don’t know where we’re going to get more.
But practically speaking, I think the bigger problem is that businesses, companies, and people are generating I guess zettabytes of data, and nobody is actually looking at any of that data or at least a small percentage.
To me, this presents an extraordinary opportunity for AI to actually give us visibility and the ability to extract insights from all this data that nobody is looking at.
So sure, we have a data problem, but not the one that people think.