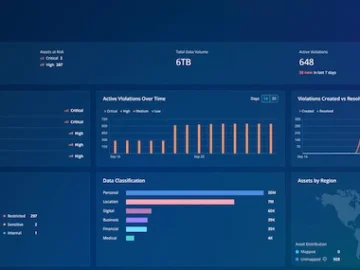
Protecting data and other enterprise assets is an increasingly challenging task, and one that touches nearly every corner of an organization. As the complexity of digital systems grows, the challenges mount.
One method that helps reign in the chaos is bringing development, security and operations together via a DevSecOps methodology, that integrates security across the IT lifecycle.
Yet, as artificial intelligence (AI) advances and machine learning (ML) moves to the center of an organization, there’s an emerging challenge: how to incorporate ML security into the broad development cycle. AI models aren’t like other software. They make predictions, recommendations and handle automation—often without a direct interface or specific code.
As such, it’s critical to develop protections and guardrails that keep AI and ML models secure. That’s where machine learning security operations (MLSecOps) enters the picture. It extends DevSecOps principles into AI and across the machine learning lifecycle. The MLSecOps framework focuses on protecting code, algorithms and data sets that touch intellectual property (IP) and other sensitive data.
Gaining a more complete view of the development cycle
To get started, it’s important to understand how DevSecOps and MLSecOps are alike, and how they differ. Both share a common path: they begin with ideation or origination across the development process. Both also train developers or data scientists about security and help them understand threat modeling. Consequently, many of the same techniques that work within DevSecOps are effective in the MLSecOps world.
This includes the concept of shift left, which aims to inject key checks, balances and protections earlier in the development process, with the goal of reducing security risks later. This approach can save money, reduce technical debt, and most importantly, sidestep real-world breaches and breakdowns. However, that’s where many of the similarities end. A traditional software application is very different from a machine learning, model-driven app.
A traditional software development task could be to develop an interface with buttons, drop down boxes and other functionality that leads a customer through a linear process, such as a purchase. As a result, looks and functionality reign supreme. Within an ML driven app, there is a focus on the model, the data that the model is trained on, and what insights the model yields. Typical use cases focus on probabilities and pattern identification, such as the likelihood that a person will buy a product, a specific credit card transaction is linked to fraud or the probability a therapy is effective in combating a disease.
Unlike in a conventional software development environment with an integrated development environment (IDE), data scientists typically write code using Jupyter Notebooks. This takes place outside of an IDE, and often outside of the traditional DevSecOps lifecycle. As a result, it’s possible for a data scientist who is not trained on secure development techniques to put sensitive data at risk, by storing unprotected secrets or other sensitive information in a notebook. Simply put, the same tools and protections used in the DevSecOps world aren’t effective for ML workloads.
The complexity of the environment also matters. Conventional development cycles usually lead directly to a software application interface or API. In the machine learning space, the focus is iterative, building a trainable model that leads to better outcomes. ML environments produce large quantities of serialized files necessary for a dynamic environment. The upshot? Organizations can become overwhelmed by the inherent complexities of versioning and integration.
What does all of this mean in practical terms? DevSecOps is complex and MLSecOps is even more complex. MLSecOps involves fast evolving and highly dynamic environments that incorporate numerous metrics and constantly changing conditions and requirements. In order to extract the full value from MLSecOps, business and IT leaders must rethink and rewire processes in order to shift left.
MLSecOps is a pathway to a more secure enterprise
Although navigating the MLOps space isn’t easy, it is critically important. In order to lower cybersecurity risk, it’s vital to have a high level of collaboration among engineers, data scientists, and security professionals. Educating data scientists about best practices is at the center of building a stronger and more dynamic security model.
Yet, there are several other steps that can make or break MLSecOps. These include: using a shift left approach to build a solid best practice foundation; gaining full visibility into the ML pipeline, including datasets, models and platforms; regularly auditing the environment and conducting vulnerability assessments for all the tools and platforms it contains; and evaluating third party models for security risks before they are integrated into an AI environment.
The ultimate goal is transparency and traceability across the machine learning supply chain. This includes a machine learning bill of materials (MLBOM), which delivers a comprehensive view into the environment and all of its components. With MLSecOps and a MLBOM in place, an enterprise can determine whether a model contains vulnerabilities or poses other types of security or compliance risks.
With an MLSecOps framework in place, it’s possible to elevate security and realize the full value of AI and machine learning.