
Software vulnerabilities are essentially errors in code that malicious actors can exploit. Advanced language models such as CodeBERT, GraphCodeBERT, and CodeT5 can detect these vulnerabilities, provide detailed analysis assessments, and even recommend patches to address them.
These models have proven to be highly effective in identifying and mitigating software vulnerabilities, making them an essential tool for any organization looking to enhance their security posture.
A tool named AIBugHunter in VSCode uses these models for adequate software security.
API security isn’t just a priority; it’s the lifeline of businesses and organizations. Yet, this interconnectivity brings with it an array of vulnerabilities that are often concealed beneath the surface.
While ChatGPT and other large language models excel in code-related tasks, no comprehensive studies have assessed their potential for the entire vulnerability workflow, including-
- Detection
- Type explanation
- Severity estimation
- Repair suggestions
Recently, the following cybersecurity researchers from Monash University, Clayton, Australia, have explored ChatGPT’s use in software vulnerability tasks, including prediction, classification, and smart contract correction:-
- Michael Fu
- Chakkrit (Kla) Tantithamthavorn
- Van Nguyen
- Trung Le
Some previous studies examined large language models in automated program repair but not the latest ChatGPT versions.
ChatGPT Vulnerability Detection
Cybersecurity researchers analyzed the ability of ChatGPT for the following four vulnerability prediction tasks:-
- Function and line-level software vulnerability prediction (SVP)
- Software vulnerability classification (SVC)
- Severity estimation
- Automated vulnerability repair (APR)
ChatGPT’s 1.7 trillion parameters vastly exceed those of source code-oriented models like CodeBERT, making prompt-based usage essential. Fine-tuning for vulnerability tasks isn’t possible due to ChatGPT’s proprietary parameters.
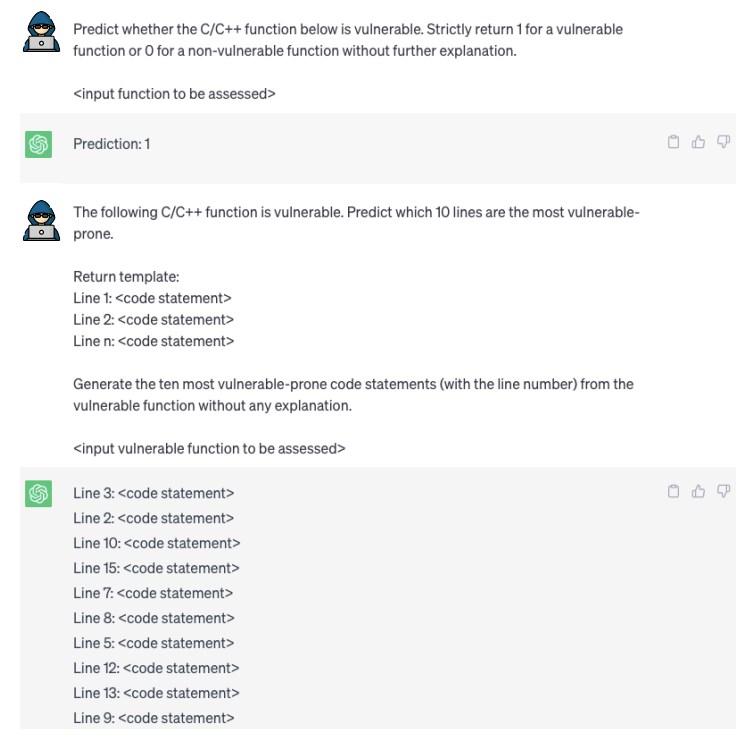
Security analysts evaluate ChatGPT (get-3.5-turbo and gpt-4) against code-specific models.
They compared it with AIBugHunter, CodeBERT, GraphCodeBERT, and VulExplainer on four vulnerability tasks using Big-Vul and CVEFixes datasets, addressing four research questions.
Here, we have mentioned all four research questions below, along with their respective results:-
(RQ1) How accurate is ChatGPT for function and line-level vulnerability predictions?
- Results: ChatGPT achieves F1-measure of 10% and 29% and top-10 accuracy of 25% and 65%, which are the lowest compared with other baseline methods.
(RQ2) How accurate is ChatGPT for vulnerability type classification?
- Results: ChatGPT achieves the lowest multiclass accuracy of 13% and 20%, 45%-52% lower than the best baseline.
(RQ3) How accurate is ChatGPT for vulnerability severity estimation?
- Results: ChatGPT gave the most inaccurate severity estimation with the highest mean squared error (MSE) of 5.4 and 5.85, while other baseline methods achieved MSE of 1.8 to 1.86.
(RQ4) How accurate is ChatGPT for automated vulnerability repair?
- Results: ChatGPT failed to generate correct repair patches, while other baselines correctly repaired 7%-30% of vulnerable functions.
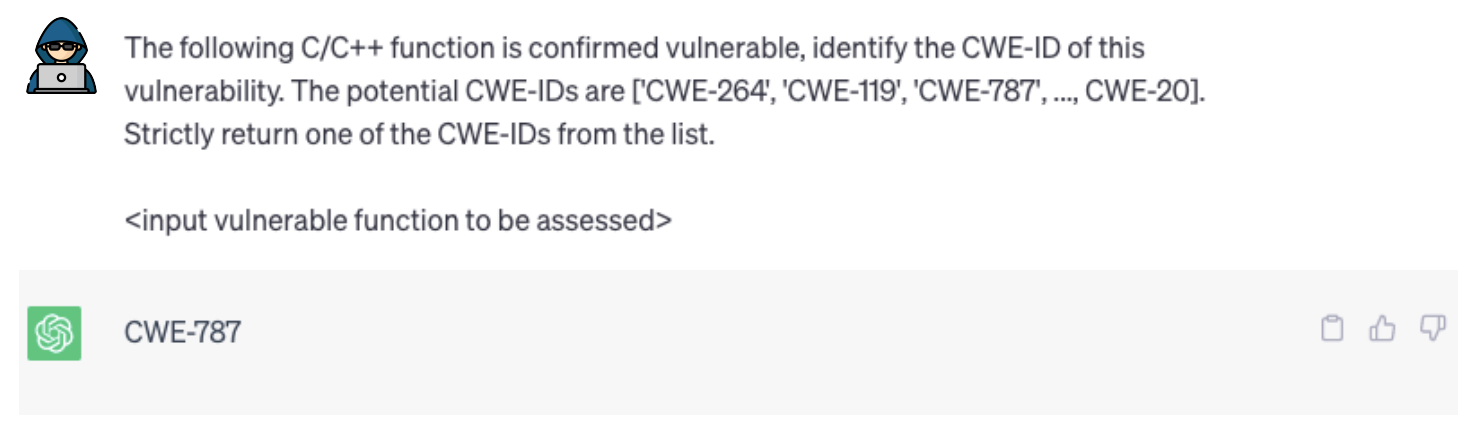
ChatGPT didn’t produce correct repair patches, whereas fine-tuned baselines repaired 7%-30%. BLEU and METEOR scores confirm baseline patches are closer to true ones.
This highlights the challenge of vulnerability repair, suggesting ChatGPT requires domain-specific fine-tuning.
Other ChatGPT Developments:
Protect yourself from vulnerabilities using Patch Manager Plus to quickly patch over 850 third-party applications. Take advantage of the free trial to ensure 100% security.




