
GraphQL is a modern query language for Application Programming Interfaces (APIs). Supported by Facebook and the GraphQL Foundation, GraphQL grew quickly and has entered the early majority phase of the technology adoption cycle, with major industry players like Shopify, GitHub and Amazon coming on board.
As with the rise of any new technology, using GraphQL came with growing pains, especially for developers who were implementing GraphQL for the first time. While GraphQL promised greater flexibility and power over traditional REST APIs, GraphQL could potentially increase the attack surface for access control vulnerabilities. Developers should look out for these issues when implementing GraphQL APIs and rely on secure defaults in production. At the same time, security researchers should pay attention to these weak spots when testing GraphQL APIs for vulnerabilities.
With a REST API, clients make HTTP requests to individual endpoints.
For example:
GET /api/user/1: Get user1POST /api/user: Create a userPUT /api/user/1: Edit user1DELETE /api/user/1: Delete user1
GraphQL replaces the standard REST API paradigm. Instead, GraphQL specifies only one endpoint to which clients send either query or mutation request types. These perform read and write operations respectively. A third request type, subscriptions, was introduced later but has been used far less often.
On the backend, developers define a GraphQL schema that includes object types and fields to represent different resources.
For example, a user would be defined as:
type User {
id: ID!
name: String!
email: String!
height(unit: LengthUnit = METER): Float
friends: [User!]!
status: Status!
}
enum LengthUnit {
METER
FOOT
}
enum Status {
FREE
PREMIUM
}
This simple example demonstrates several powerful features of GraphQL. It supports a list of other object types (friends), variables (unit), and enums (status). In addition, developers write resolvers, which define how the backend fetches results from the database for a GraphQL request.
To illustrate this, let’s assume that a developer has defined the following query in the schema:
{
"name": "getUser",
"description": null,
"args": [
{
"name": "id",
"description": null,
"type": {
"kind": "SCALAR",
"name": "ID",
"ofType": null
},
"defaultValue": null
}
],
"type": {
"kind": "OBJECT",
"name": "User",
"ofType": null
},
"isDeprecated": false,
"deprecationReason": null
}
On the client side, a user would make the getUser query and retrieve the name and email fields through the following POST request:
POST /graphql
Host: example.com
Content-Type: application/json
{
"query":"query getUser($id:ID!) { getUser(id:$id) { name email }}",
"variables":{"id":1},
"operationName":"getUser"
}
On the backend, the GraphQL layer would parse the request and pass it to the matching resolver:
Query: {
user(obj, args, context, info) {
return context.db.loadUserByID(args.id).then(
userData => new User(userData)
)
}
}
Here, args refers to the arguments provided to the field in the GraphQL query. In this case, args.id is 1.
Finally, the requested data would be returned to the client:
You may have noticed that the User object type also includes the friends field, which references other User objects. Clients can use this to query other fields on related User objects.
POST /graphql
Host: example.com
Content-Type: application/json
{
"query":"query getUser($id:ID!) { getUser(id:$id) { name email friends { email }}}",
"variables":{"id":1},
"operationName":"getUser"
}
Thus, instead of manually defining individual API endpoints and controller functions, developers can leverage the flexibility of GraphQL to craft complex queries on the client side without having to modify the backend. This makes GraphQL popular with serverless implementations like Apollo Server with AWS Lambda.
Remember the familiar line — with great power comes great responsibility? While GraphQL’s flexibility is a strong advantage, it can be abused to exploit access control and information disclosure vulnerabilities.
Consider the simple User object type and query. You might reasonably expect that a user can query the email of their friends. But what about the email of their friends’ friends? Without seeking authorisation, an attacker could easily obtain the emails of second-degree and third-degree connections using the following:
query Users($id: ID!) {
user(id: $id) {
name
friends {
friends {
email
friends {
email
}
}
}
}
}
In the classic REST paradigm, developers implement access controls for each individual controller or model hook. While potentially violating the Don’t Repeat Yourself (DRY) principle, this gives developers greater control over each call’s access controls.
GraphQL advises developers to delegate authorisation to the business logic layer rather than the GraphQL layer.
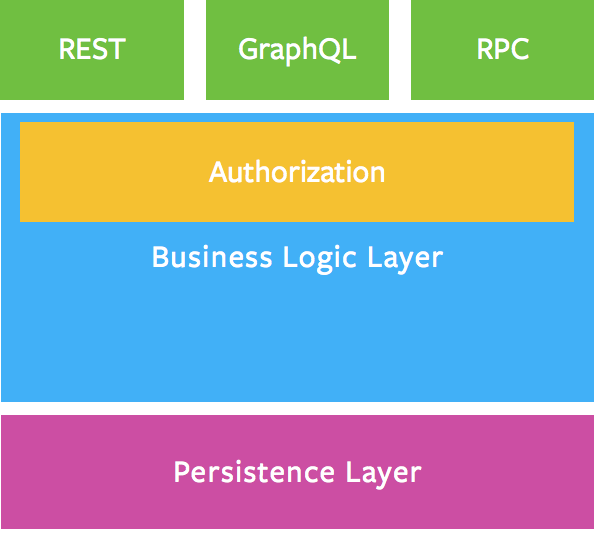
Business Logic Layer from GraphQL
As such, the authorisation logic sits below the GraphQL resolver. For instance, in this sample from GraphQL:
//Authorization logic lives inside postRepository
var postRepository = require('postRepository');
var postType = new GraphQLObjectType({
name: 'Post',
fields: {
body: {
type: GraphQLString,
resolve: (post, args, context, { rootValue }) => {
return postRepository.getBody(context.user, post);
}
}
}
});
postRepository.getBody validates access controls in the business logic layer.
However, this isn’t enforced by the GraphQL specification. GraphQL recognises that it may be “tempting” for developers to place the authorisation logic incorrectly in the GraphQL layer. Unfortunately, developers fall into this trap far too often, creating holes in the access control layer.
So how should security researchers approach a GraphQL API? GraphQL recommends that developers “think in graphs” when modelling their data, and researchers should do the same. We can draw parallels to what I call “second-order Insecure Direct Object References (IDORs)” in the classic REST paradigm.
For example, in a REST API, while the following API call may be properly protected:
GET /api/user/1
A “second-order” API call may not be adequately protected:
GET /api/user/1/photo/6
The backend logic may have validated that the user requesting for user number 1 has read permissions to that user. However it has failed to check if they should also have access to photo number 6.
The same applies to GraphQL calls, except that with a graph schema, the number of possible paths increases exponentially. Take a social media photo for example: What if an attacker queries the users who have liked a photo, and in turn accesses their photos?
query Users($id: ID!) {
user(id: $id) {
name
photos {
image
likes {
user {
photos {
image
}
}
}
}
}
}
What about the likes on those photos? The chain continues. In short, a security researcher should seek to “close the loop” in the graph and find paths towards their target object. Dominic Couture from GitLab explains this comprehensively in his post about his graphql-path-enum tool.
In most implementations of GraphQL APIs, you should be able to quickly identify the GraphQL endpoint because they tend to be simply /graphql or /graph. You can also identify them based on the requests made to these endpoints.
POST /graphql
Host: example.com
Content-Type: application/json
{"query": "query AllUsers { allUsers{ id } }"}
You should look out for key words like query and mutation. In addition, some GraphQL implementations use GET requests that look like this: GET /graphql?query=….
Once you’ve identified the endpoint, you should extract the GraphQL schema. Thankfully, the GraphQL specification supports such “introspection” queries that return the entire schema. This allows developers to quickly build and debug GraphQL queries. These introspection queries perform a similar function as the API call documentation tools, such as Swagger, in REST APIs.
We can adapt the introspection query from this gist:
query IntrospectionQuery {
__schema {
queryType {
name
}
mutationType {
name
}
subscriptionType {
name
}
types {
…FullType
}
directives {
name
description
args {
…InputValue
}
locations
}
}
}
fragment FullType on __Type {
kind
name
description
fields(includeDeprecated: true) {
name
description
args {
…InputValue
}
type {
…TypeRef
}
isDeprecated
deprecationReason
}
inputFields {
…InputValue
}
interfaces {
…TypeRef
}
enumValues(includeDeprecated: true) {
name
description
isDeprecated
deprecationReason
}
possibleTypes {
…TypeRef
}
}
fragment InputValue on __InputValue {
name
description
type {
…TypeRef
}
defaultValue
}
fragment TypeRef on __Type {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType {
kind
name
}
}
}
}
Of course, you will have to encode this for the method that the call is made with. To match the standard POST /graphql JSON format, use:
POST /graphql
Host: example.com
Content-Type: application/json
{"query": "query IntrospectionQuery {__schema {queryType { name },mutationType { name },subscriptionType { name },types {…FullType},directives {name,description,args {…InputValue},locations}}}\nfragment FullType on __Type {kind,name,description,fields(includeDeprecated: true) {name,description,args {…InputValue},type {…TypeRef},isDeprecated,deprecationReason},inputFields {…InputValue},interfaces {…TypeRef},enumValues(includeDeprecated: true) {name,description,isDeprecated,deprecationReason},possibleTypes {…TypeRef}}\nfragment InputValue on __InputValue {name,description,type { …TypeRef },defaultValue}\nfragment TypeRef on __Type {kind,name,ofType {kind,name,ofType {kind,name,ofType {kind,name}}}}"}
Hopefully, this will return the entire schema so you can begin hunting for different paths to your desired object type. Several GraphQL frameworks, such as Apollo, acknowledge the dangers of exposing introspection queries and have disabled them in production by default. In such cases, you will have to feel your way forward by patiently brute-forcing and enumerating possible object types and fields. For Apollo, the server helpfully returns Error: Unknown type "X". Did you mean "Y"? for a type or field that’s close to the actual value.
Security researchers should uncover as much of the original schema as possible. If you have the full schema, feel free to run it through tools like graphql-path-enum to enumerate different paths from one query to a target object type. In the example given by graphql-path-enum, if the target object type in a schema is Skill, the researcher should run:
$ graphql-path-enum -i ./schema.json -t Skill
Found 27 ways to reach the "Skill" node from the "Query" node:
— Query (assignable_teams) -> Team (audit_log_items) -> AuditLogItem (source_user) -> User (pentester_profile) -> PentesterProfile (skills) -> Skill
— Query (checklist_check) -> ChecklistCheck (checklist) -> Checklist (team) -> Team (audit_log_items) -> AuditLogItem (source_user) -> User (pentester_profile) -> PentesterProfile (skills) -> Skill
— Query (checklist_check_response) -> ChecklistCheckResponse (checklist_check) -> ChecklistCheck (checklist) -> Checklist (team) -> Team (audit_log_items) -> AuditLogItem (source_user) -> User (pentester_profile) -> PentesterProfile (skills) -> Skill
— Query (checklist_checks) -> ChecklistCheck (checklist) -> Checklist (team) -> Team (audit_log_items) -> AuditLogItem (source_user) -> User (pentester_profile) -> PentesterProfile (skills) -> Skill
— Query (clusters) -> Cluster (weaknesses) -> Weakness (critical_reports) -> TeamMemberGroupConnection (edges) -> TeamMemberGroupEdge (node) -> TeamMemberGroup (team_members) -> TeamMember (team) -> Team (audit_log_items) -> AuditLogItem (source_user) -> User (pentester_profile) -> PentesterProfile (skills) -> Skill
…
The results return different paths in the schema to reach Skill objects through nested queries and linked object types.
Security researchers should also go through the schema manually to discover paths that graphql-path-enum might have missed. Since the tool also requires a GraphQL schema to work, researchers that are unable to extract the full schema will also have to rely on manual inspection. To do this, consider various object types the attacker has access to, find their linked object types, and follow these links to the protected resource. Next, test these queries for access control issues.
For mutations, the approach is similar. Beyond testing for direct access control issues (mutations on objects you should not have access to), you will need to check the return values of mutations for linked object types.
GraphQL adds greater flexibility and depth to APIs by querying objects through the graph paradigm. However, it is not a panacea for access control vulnerabilities. GraphQL APIs are prone to the same authorisation and authentication issues that affect REST APIs. Additionally, its access controls still depend on developers to define appropriate business logic or model hooks, increasing the potential for human errors.
Developers should move their access controls as close to the persistence (model) layer as possible, and when in doubt, rely on frameworks with sane defaults like Apollo. In particular, Apollo recommends performing authorisation checks in data models:
Since the very beginning, we’ve recommended moving the actual data fetching and transformation logic from resolvers to centralized Model objects that each represent a concept from your application: User, Post, etc. This allows you to make your resolvers a thin routing layer, and put all of your business logic in one place.
For instance, the model for User would look like this:
export const generateUserModel = ({ user }) => ({
getAll: () => {
if(!user || !user.roles.includes('admin')) return null;
return fetch('http://myurl.com/users');
},
…
});
By moving the authorisation logic to the model layer instead of spreading it across different controllers, developers can define a single “source of truth”.
In the long run, as GraphQL enjoys even greater adoption and reaches the late majority stage of the technology adoption cycle, more developers will implement GraphQL for the first time. Developers must carefully consider the attack surface of their GraphQL schemas and implement secure access controls to protect user data.
Special thanks to Dominic Couture, Kenneth Tan, Medha Lim, Serene Chan, and Teck Chung Khor for their inputs.



![A Logical Approach to the Council on Foreign Relations (CFR) and One World Government [NWO] Conspiracy](https://image.cybernoz.com/wp-content/uploads/2025/04/A-Logical-Approach-to-the-Council-on-Foreign-Relations-CFR.jpg)


