
On Tuesday, Cloudflare experienced its worst outage in 6 years, blocking access to many websites and online platforms for almost 6 hours after a change to database access controls triggered a cascading failure across its Global Network.
The company’s Global Network is a distributed infrastructure of servers and data centers across more than 120 countries, providing content delivery, security, and performance optimization services and connecting Cloudflare to over 13,000 networks, including every major ISP, cloud provider, and enterprise worldwide.
Matthew Prince, the company’s CEO, said in a post-mortem published after the outage was mitigated that the service disruptions were not caused by a cyberattack.

“The issue was not caused, directly or indirectly, by a cyber attack or malicious activity of any kind. Instead, it was triggered by a change to one of our database systems’ permissions which caused the database to output multiple entries into a “feature file” used by our Bot Management system,” Prince said.
The outage began at 11:28 UTC when a routine database permissions update caused Cloudflare’s Bot Management system to generate an oversized configuration file containing duplicate entries. The file, which exceeded the built-in size limits, caused the software to crash while routing traffic across Cloudflare’s network.
This database query returned duplicate column metadata after permissions changes, doubling the feature file from approximately 60 features to over 200, exceeding the system’s hardcoded 200-feature limit designed to prevent unbounded memory consumption.
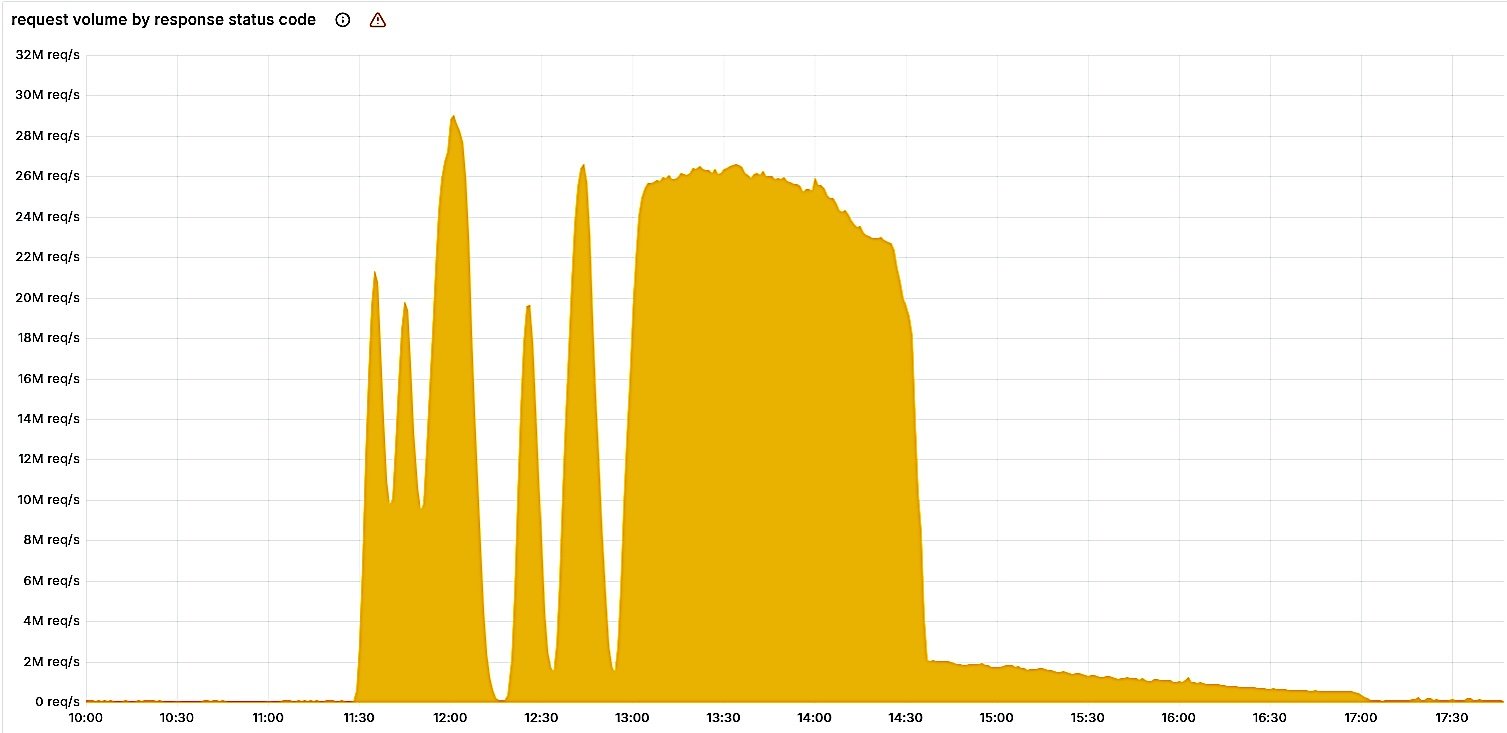
Every five minutes, a query generated either correct or faulty configuration files, depending on which cluster nodes had been updated, causing the network to fluctuate between working and failing states.
Additionally, when the oversized file propagated across network machines, the Bot Management module’s Rust code triggered a system panic and 5xx errors, crashing the core proxy system that handles traffic processing.
Core traffic returned to normal by 14:30 UTC after Cloudflare engineers identified the root cause and replaced the problematic file with an earlier version. All systems were fully operational by 17:06 UTC. The outage affected Cloudflare’s core CDN and security services, Turnstile, Workers KV, dashboard access, email security, and access authentication.
“We are sorry for the impact to our customers and to the Internet in general. Given Cloudflare’s importance in the Internet ecosystem any outage of any of our systems is unacceptable,” Prince added.
“Today was Cloudflare’s worst outage since 2019. We’ve had outages that have made our dashboard unavailable. Some that have caused newer features to not be available for a period of time. But in the last 6+ years we’ve not had another outage that has caused the majority of core traffic to stop flowing through our network.”
Cloudflare mitigated another massive outage in June, which caused Zero Trust WARP connectivity issues and Access authentication failures across multiple regions, and also impacted Google Cloud infrastructure.
In October, Amazon also addressed an outage triggered by a major DNS failure that disrupted connectivity to millions of websites using its Amazon Web Services (AWS) cloud computing platform.

It’s budget season! Over 300 CISOs and security leaders have shared how they’re planning, spending, and prioritizing for the year ahead. This report compiles their insights, allowing readers to benchmark strategies, identify emerging trends, and compare their priorities as they head into 2026.
Learn how top leaders are turning investment into measurable impact.






