Cloudflare’s widely used 1.1.1.1 DNS resolver service experienced a significant 62-minute global outage on July 14, 2025, affecting millions of users worldwide from 21:52 UTC to 22:54 UTC.
Contrary to initial speculation, the company has confirmed that the outage was caused by an internal configuration error rather than a BGP attack, though a coincidental BGP hijack by Tata Communications India (AS4755) was observed during the incident.
Key Takeaways
1. Cloudflare's DNS service experienced a 62-minute global outage on July 14, 2025, impacting millions of users.
2. The outage was caused by a misconfigured system update from June 6, not a BGP attack.
3. Service was restored by reverting configurations; Cloudflare will upgrade legacy systems to prevent recurrence.
Cloudflare Recent 1.1.1.1 Outage
The root cause of the outage was traced back to a configuration change made on June 6, 2025, during preparations for a Data Localization Suite (DLS) service.

During this release, prefixes associated with the 1.1.1.1 Resolver service were inadvertently included alongside prefixes intended for the new DLS service.
This misconfiguration remained dormant in the production network until July 14, when a second configuration change was made to attach a test location to the non-production service, triggering a global refresh of network configuration.
The error caused the 1.1.1.1 Resolver prefixes to be withdrawn from production Cloudflare data centers globally, effectively making the service unreachable.
The affected IP ranges included critical addresses such as 1.1.1.0/24, 1.0.0.0/24, 2606:4700:4700::/48, and several other IPv4 and IPv6 prefixes.

DNS traffic over UDP, TCP, and DNS over TLS (DoT) dropped immediately, while DNS-over-HTTPS (DoH) traffic remained relatively stable as it uses the domain cloudflare-dns.com rather than IP addresses.
Coincidental BGP Hijack
During the outage investigation, Cloudflare discovered that Tata Communications India (AS4755) had started advertising the 1.1.1.0/24 prefix, creating what appeared to be a BGP hijack scenario.

However, company engineers emphasized that this hijack was not the cause of the outage but rather an unrelated issue that became visible when Cloudflare withdrew its routes.
The BGP hijack occurred at 21:54 UTC, two minutes after the DNS traffic began dropping globally.
This incident highlighted the complexity of managing anycast routing, the method Cloudflare uses to distribute traffic across multiple global locations for improved performance and capacity.
When problems occur with address space advertisements, they can result in global outages affecting all users simultaneously.
Prevention Measures
Cloudflare initiated a revert to the previous configuration at 22:20 UTC, which restored traffic levels to approximately 77% of normal capacity.
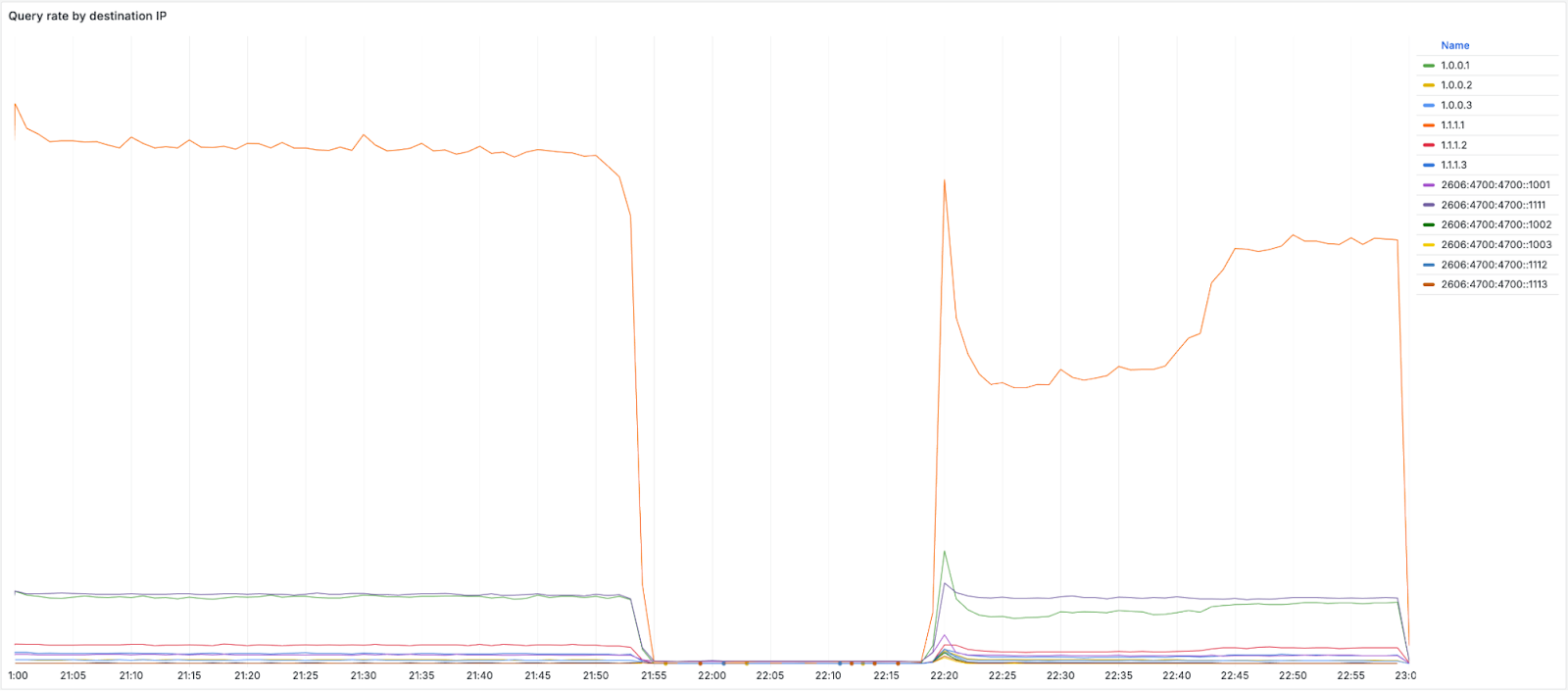
The remaining 23% of edge servers required reconfiguration through the company’s change management system, which was accelerated given the incident’s severity. 22:54 UTC achieved full service restoration.
To prevent similar incidents, Cloudflare announced plans to deprecate legacy systems that lack progressive deployment methodologies and implement staged addressing deployments with health monitoring capabilities.
Investigate live malware behavior, trace every step of an attack, and make faster, smarter security decisions -> Try ANY.RUN now