The text-to-dense representation techniques vary, evolving from character bi-grams to advanced subword vectorizers, combating OOV challenges like adversarial attacks and typos.
As the strategies include subword-level tokenization and decomposing unknown words into n-grams for effective neural network training.
Researchers at Google recently developed and unveiled a new resilient and efficient text vectorizer dubbed “RETVec,” which will defend Gmail users against malicious emails and spam.
StorageGuard scans, detects, and fixes security misconfigurations and vulnerabilities across hundreds of storage and backup devices.
RETVec
RETVec is an efficient, multilingual, next-gen text vectorizer with built-in adversarial resilience. This next-gen text vectorizer is resilient to character-level manipulations like-
- Insertion
- Deletion
- Typos
- Homoglyphs
- LEET substitution
There are two layers in the RETVec character encoder, and here below, we have mentioned those layers:-
- Integerizer layer
- Binarizer layer
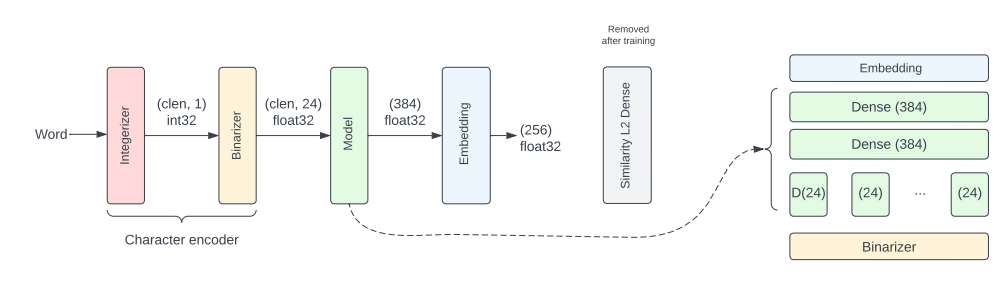
RETVec uses a unique character encoder, handling UTF-8 efficiently. It effortlessly supports 100+ languages without lookup tables or fixed vocabulary. Also, being a layer, it seamlessly fits into any TF model without extra pre-processing.
RETVec Binarizer boosts word representation but lacks competitiveness. Researchers enhance it with a small model, boosting accuracy and outperforming others.
TensorFlow models easily employ RETVec for string vectorization in just one line. Besides this, the raw strings were handled with built-in pre-processing.
Moreover, this system also works perfectly for on-device mobile and web use cases since it supports the:-
Researchers tested RETVec against adversarial content using a Google spam filter. Swapping SentencePiece with RETVec improved spam detection by 38% at a 0.80% false positive rate, reducing latency by 30%.
This suggests RETVec is competitive for real-world tasks, boosting confidence in its effectiveness.
How to optimize RETVec for better multilingual skills, robustness, and smaller models in large language models (LLMs) is a key question. For smaller LLMs, where the vocabulary layer can be over 20% of the parameters, RETVec eliminates it.
Yet, using RETVec in generative models poses challenges, as its 256-float embedding doesn’t directly convert to softmax output. A new training method compatible with text generation is needed.
Experimenting with character-by-character decoding and the VQ-VAE model renders indecisive results. Future work addresses these limitations and explores RETVec’s use as a word embedding, replacing GloVe and word2vec and training text similarity models with its character encoder.
Installation
To install the latest TensorFlow version of RETVec, you can use “pip”:-
Besides this, on TensorFlow 2.6+ and Python 3.8+, the RETVec has already been tested.
Experience how StorageGuard eliminates the security blind spots in your storage systems by trying a 14-day free trial.