
Researchers have demonstrated a new acoustic side-channel attack on keyboards that can deduce user input based on their typing patterns, even in poor conditions, such as environments with noise.
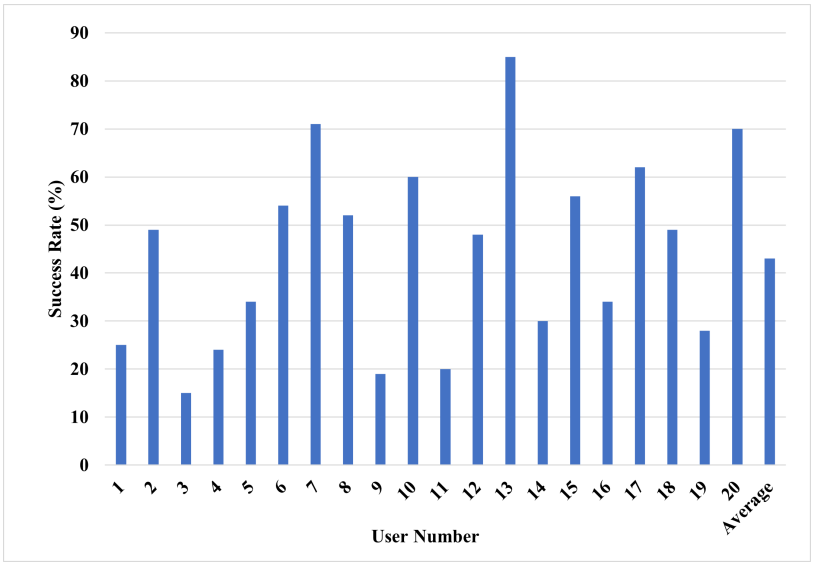
Though the method achieves an average success rate of 43%, which is significantly lower than other methods presented in the past, it it does not require controlled recording conditions or a specific typing platform.
This makes it more applicable in real attacks, and depending on some target-specific parameters, it can produce enough reliable data to decipher the overall target’s input with some post-capture analysis.
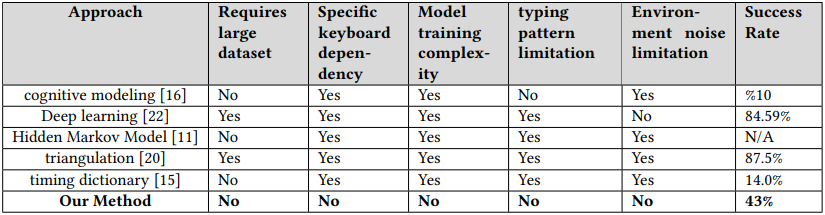
The acoustic attack
Researchers Alireza Taheritajar and Reza Rahaeimehr from Augusta University in the U.S. have published a technical paper presenting the details of their unique acoustic side-channel method.
The attack leverages the distinctive sound emissions of different keystrokes and the typing pattern of users captured by specialized software to gather a dataset.
It is crucial to gather some typing samples from the target so that specific keystrokes and words can be correlated with sound waves.
The paper does delve on the possible methods for capturing text, but it could be through malware, malicious websites or browser extensions, compromised apps, cross-site scripting, or compromised USB keyboards.
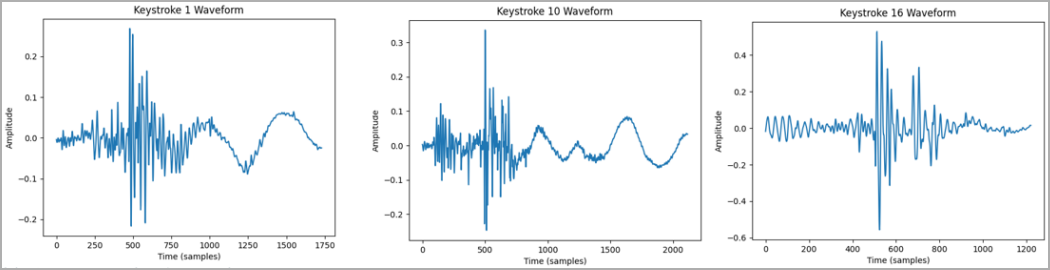
The target’s typing may be recorded by using a concealed microphone near them or remotely using compromised devices in proximity, such as smartphones, laptops, or smart speakers.
The captured dataset includes typing samples under various conditions, so multiple typing sessions must be recorded, which is crucial for the attack’s success. However, the researchers say the dataset doesn’t have to be particularly large.
The dataset is then used to train a statistical model that produces a comprehensive profile of the target’s individual typing patterns based on the time intervals between keystrokes.
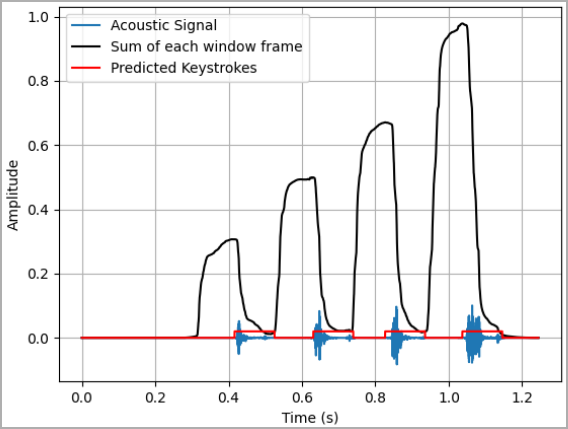
The researchers found that accepting a 5% deviation for the statistical model is crucial, as typing behavior varies slightly even when a person types the same word twice.
For example, any recorded interval between A and B that falls between 95 milliseconds (100 – 5%) and 105 milliseconds (100 + 5%) could be considered a match.
The deviation also helps to mitigate the impact of errors or noise in the recording, ensuring that minor discrepancies don’t lead to a mismatch.
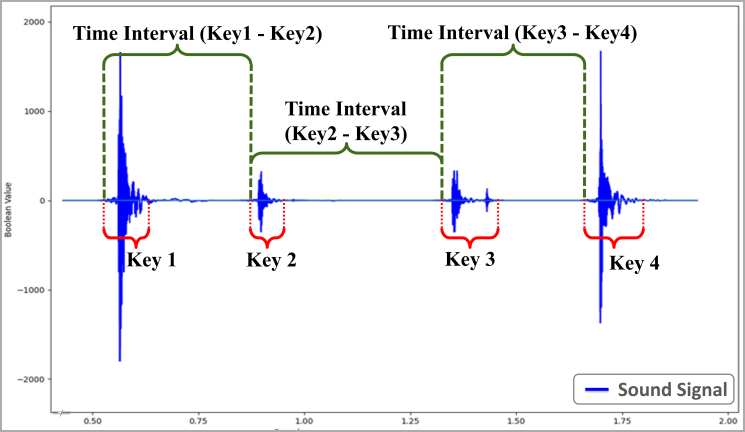
The method predicts the typed text by analyzing audio recordings of keyboard activity, with the accuracy enhanced by filtering predictions through an English dictionary.
What makes the attack different compared to other approaches is that it can reach a typing prediction accuracy of 43% (on average) even when:
- the recordings contain environmental noise
- the recorded typing sessions for the same target took place on different keyboard models
- the recordings were taken using a low-quality microphone
- the target is free to use any typing style
On the other hand, the method has limitations that sometimes make the attack ineffective.
For example, people who rarely use a computer and haven’t developed a consistent typing pattern, or professional typists who type very fast, may be difficult to profile.
The test results for 20 test subjects have produced a broad range of success, from 15% to up to 85%, making some subjects far more predictable and susceptible than others.
The researchers also noted that the amplitude of the produced waveform is less accentuated when using silent keyboards (membrane-based or mechanical switches with sound dampener), which can hamper the training effectiveness for the prediction model and lower the keystroke detection rates.






