
LLMs have reshaped content generation, making understanding jailbreak attacks and prevention techniques challenging. Surprisingly, there’s a scarcity of public disclosures on countermeasures employed in chatbot services that are commercial LLM-based.
A practical study has been conducted by cybersecurity analysts from the following universities to bridge knowledge gaps, comprehensively understanding jailbreak mechanisms across diverse LLM chatbots while assessing the effectiveness of existing jailbreak attacks:-
- Nanyang Technological University
- University of New South Wales
- Huazhong University of Science and Technology
- Virginia Tech
Experts evaluate popular LLM chatbots (ChatGPT, Bing Chat, and Bard), testing their responses to previously researched prompts. The study reveals that OpenAI’s chatbots are vulnerable to existing jailbreak prompts, while Bard and Bing Chat exhibit greater resistance.
LLM Jailbreak
To fortify jailbreak defenses in LLMs, security researchers recommend the following things:-
- Augmenting ethical and policy-based measures
- Refining moderation systems
- Incorporating contextual analysis
- Implementing automated stress testing
While their contributions can be summarized as follows:-
- Reverse-Engineering Undisclosed Defenses
- Bypassing LLM Defenses
- Automated Jailbreak Generation
- Jailbreak Generalization Across Patterns and LLMs

Jailbreak exploits prompt manipulation to bypass usage policy measures in LLM chatbots, enabling the generation of responses and malicious content that violate the own policies of the chatbot.
Jailbreaking a chatbot involves crafting a prompt to conceal malicious questions and surpass protection boundaries. By simulating an experiment, the jailbreak prompt manipulates the LLM to generate responses that could potentially aid in malware creation and distribution.
Time-based LLM Testing
Experts conduct a comprehensive analysis by abstracting LLM chatbot services into a structured model comprising an LLM-based generator and a content moderator. This practical abstraction captures the essential dynamics without requiring in-depth knowledge of the internals.

Uncertainties remain in the abstracted black-box system, including:-
- Content moderator’s input question monitoring
- LLM-generated data stream monitoring
- Post-generation output checks
- Content moderator mechanisms

Workflow
The security analysts’ workflow emphasizes preserving the original semantics of the initial jailbreak prompt throughout its transformed variant, reflecting the design rationale.
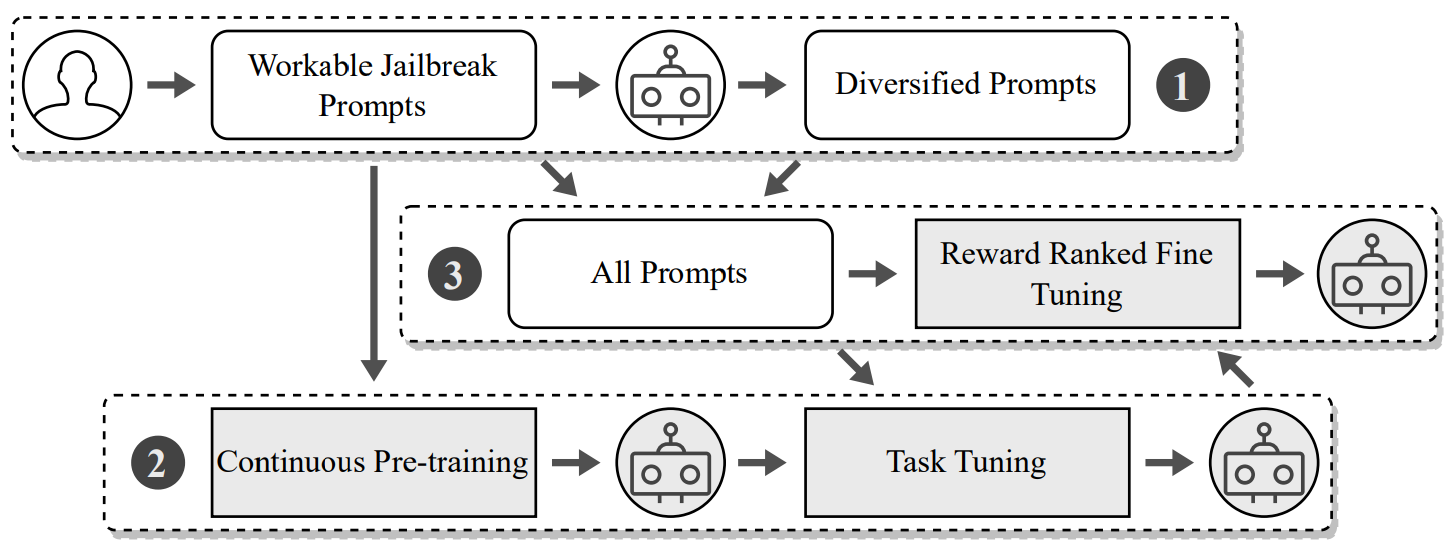
While the complete methodology begins with:-
- Dataset Building and Augmentation
- Continuous Pretraining and Task Tuning
- Reward Ranked Fine Tuning
The analysts leverage LLMs to automatically generate successful jailbreak prompts using a methodology based on text-style transfer in NLP.
Utilizing a fine-tuned LLM, their automated pipeline expands the range of prompt variants by infusing domain-specific jailbreaking knowledge.
However, apart from this, in this analysis, the cybersecurity researchers mainly used GPT-3.5, GPT-4, and Vicuna (An Open-Source Chatbot Impressing GPT-4) as benchmarks.
This analysis evaluates mainstream LLM chatbot services, highlighting their vulnerability to jailbreak attacks. Introducing JAILBREAKER, a novel framework that analyzes defenses and generates universal jailbreak prompts with a 21.58% success rate.
Findings and recommendations are responsibly shared with providers, enabling robust safeguards against the abuse of LLM modules.






