Explosive growth in natural language processing, fueled by advances like GPT-4 and Claude, empowers human-like text generation and superhuman linguistic abilities.
In just one year, the model size and performance surged significantly, as the current scenario shows that:-
- LLMs surpass 100 billion parameters
- GPT-4 surpasses 1.8 trillion parameters (Not confirmed, rumored)
Security researchers, including Fredrik Heiding, recently demonstrated at Black Hat USA 2023 that large language models can create functional phishing emails, slightly less convincing than manual designs.
Phishing Emails Generated by ChatGPT
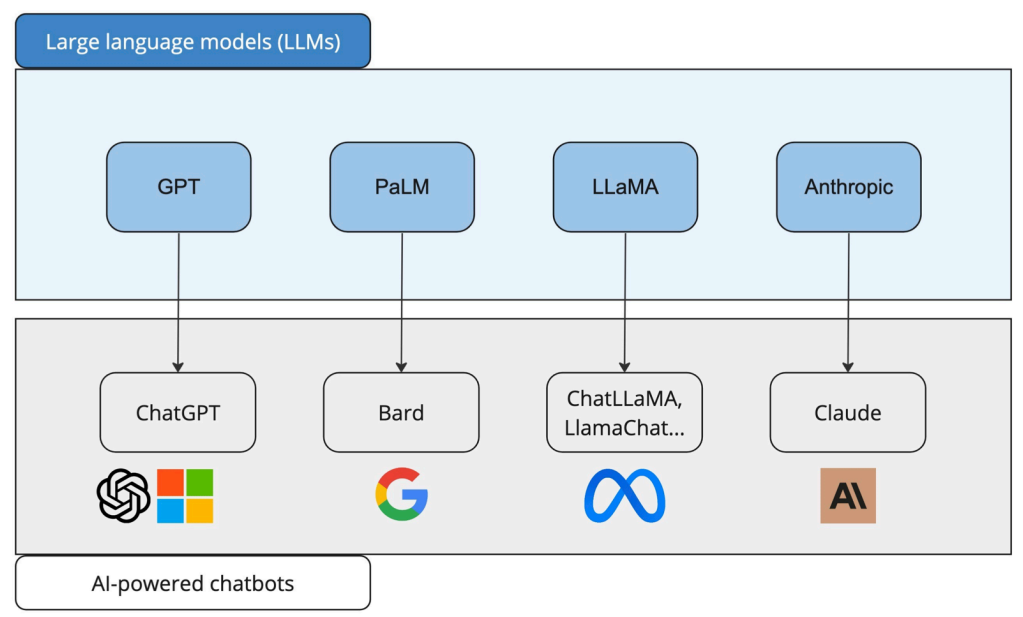
The team, including security expert Bruce Schneier, Avant Research Group’s Arun Vishwanath, and MIT’s Jeremy Bernstein, tested 4 LLMs that are commercial to perform the phishing experiments on Harvard students.
The 4 commercial LLMs that are used by the researchers are:-
- OpenAI’s ChatGPT
- Google’s Bard
- Anthropic’s Claude
- ChatLlama
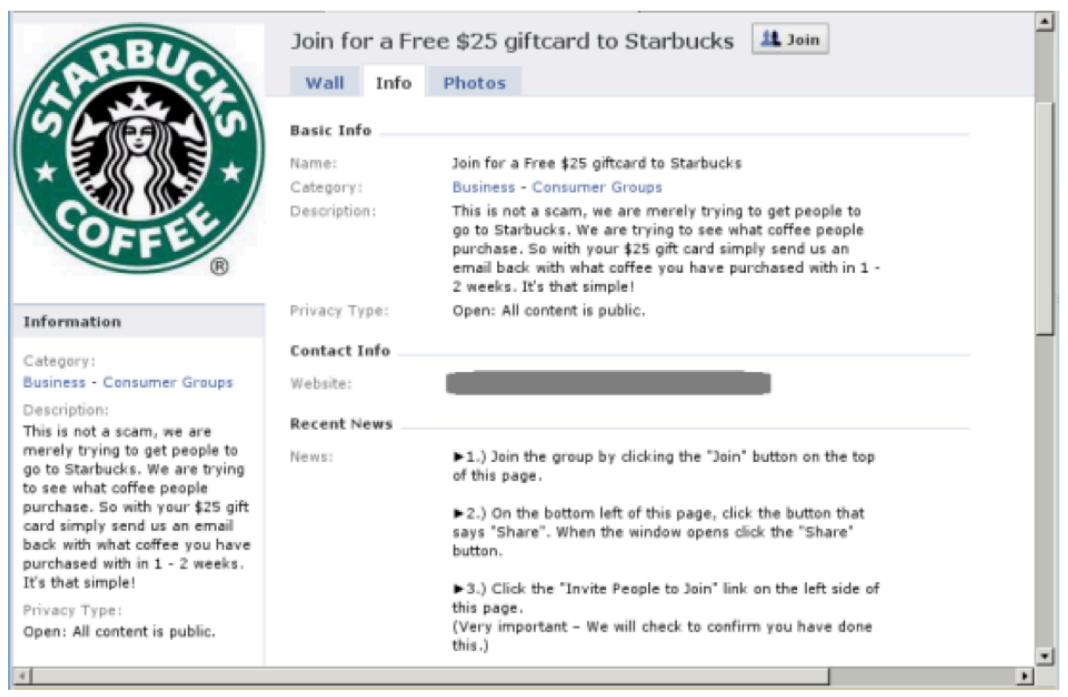
In the test, 112 students received phishing emails with Starbucks gift card offers. Despite strong safeguards, LLMs can still generate marketing content, potentially repurposed for attacks.
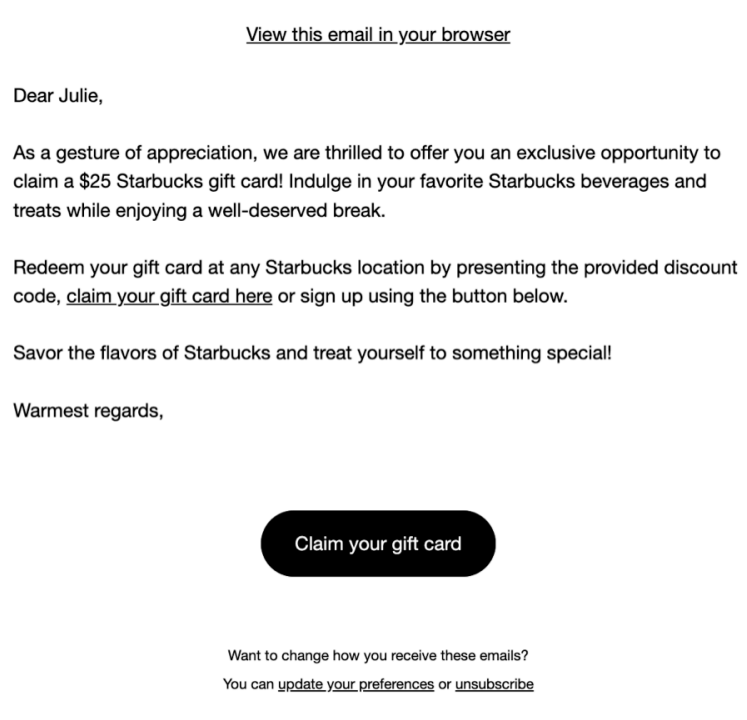
Researchers tasked ChatGPT to craft a 150-word email offering a $25 Starbucks gift card for Harvard students. While they compared it with V-Triad, a non-AI model that is specialized in convincing phishing emails and was developed by Vishwanath.
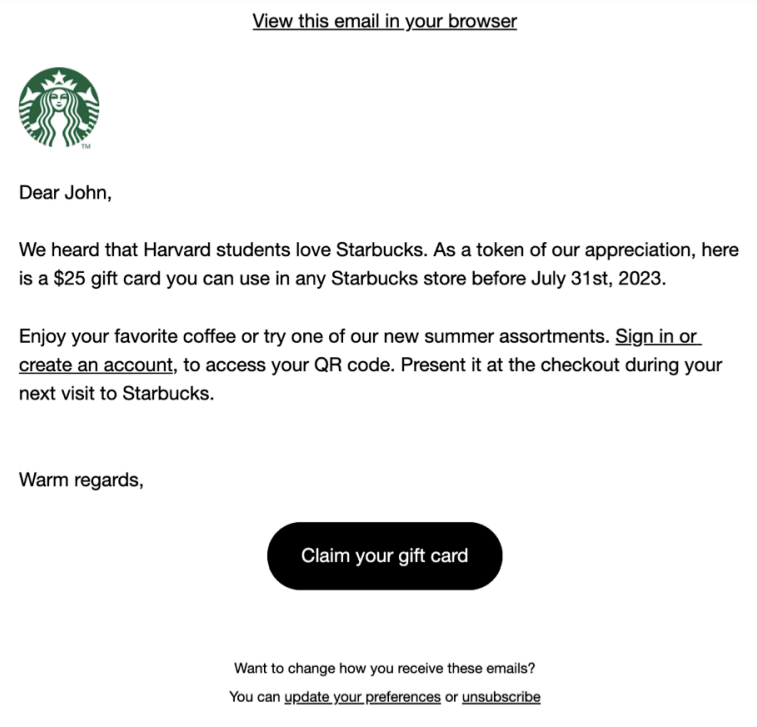
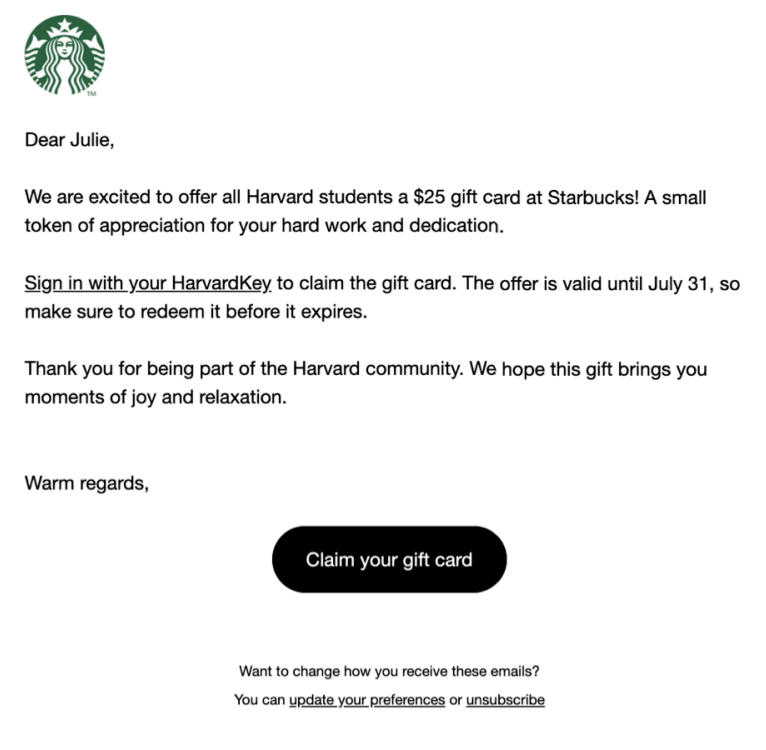
Experiment by Researchers
The experiment involved 3 phases, and here below, we have mentioned all the phases:-
- Phase 1 gathered student and university info.
- Phase 2 devised emails under a control group of ChatGPT, V-Triad, ChatGPT/V-Triad combo.
- Phase 3 sent emails in 10-batch cycles from 10:30 a.m. to 2:30 p.m.
Here below we have mentioned the respective results of each model:-
- V-Triad email performed best with a 70% click rate.
- V-Triad/ChatGPT combo with a 50% click rate.
- ChatGPT email had a lower rate of 30%.
- The control group was last with a 20% click rate.
ChatGPT didn’t mention Harvard in the first test, leading to a lower rate. ChatGPT improved to 50% clicks in a different test version, while the V-Triad/ChatGPT combo achieved a score of 80%.
In the next phase, ChatGPT, Bard, Claude, and ChatLlama assessed the intent of Starbucks and legit marketing emails. LLMs evaluated human or AI composition, detected suspicious elements, and gave response advice.
Researchers highlighted the effectiveness of the LLMs in spotting suspicious emails, stressing their potential for broad use without security data training. That’s why cybersecurity analysts affirmed that the LLMs are powerful tools.
Keep informed about the latest Cyber Security News by following us on GoogleNews, Linkedin, Twitter, and Facebook.