
At Detectify, we help customers secure their attack surface. To effectively and comprehensively test their assets, we must send a very high volume of requests to their systems, which brings the potential risk of overloading their servers. Naturally, we addressed this challenge to ensure our testing delivers maximum value to our customers while being conducted safely with our rate limiter.
After introducing our engine framework and deep diving inside the tech that monitors our customers’ attack surface, this Under the Hood blog post uncovers an important piece in the puzzle: how our rate limiter service works to make all Detectify scanning safe.
The need for the rate limiter
In our previous post, we explained the techniques that we have in place to flatten the curve of security tests that an engine performs on our customers’ systems, avoiding spikes that could overload their servers. As we continuously add more security tests to our research inventory, and with several engines working simultaneously, one can imagine that the combined load from all tests could reach significant levels and potentially create issues for our customers.
To address this, we introduced a global rate limiter designed to limit the maximum number of requests per second directed at any given target. Sensible defaults are in place, and customers have the flexibility to configure this limit based on their needs.
The combined load of engines’ tests towards customers would increase unchecked without a rate limiter
The product requirements
Before jumping into the rate limiter solution, it was important to understand the requirements for our rate limiter.
As a concept, rate limiting is nothing new in software engineering, and there are many tools available for addressing rate limiting challenges. However, we needed to determine if there was anything unique about our situation that would require a custom solution, or if an off-the-shelf product would suffice.
We explored several popular open-source tools and cloud-based solutions. Unfortunately, during our analysis, we could not find any option that fit our criteria. Detectify applies the limit on an origin basis (combination of scheme, hostname and port number), and needs to allow for individual target and highly dynamic configurations. Most existing tools fell short in this area, leading us to the decision to implement our own rate limiter.

Individual target rate limiting configurations, that can change at any time
The literature
Rate limiting is a well-known concept in software engineering. Although we built our own, we did not have to start from scratch. We researched various types of rate limiting, including blocking, throttling, and shaping. We also explored the most commonly used algorithms, such as token bucket, leaky bucket, fixed window counter, and sliding window counter, among others. Additionally, we looked into different topologies that we could use.
Our goal was to keep the implementation as straightforward as possible while meeting our requirements. Ultimately, we decided to implement a blocking token bucket rate limiter. Interestingly, given our security testing needs and how “deep in the stack” some security tests are, we landed on a service admission approach rather than the more common proxy approach.
In short, a blocking rate limiter denies requests to a target when the limit is exceeded. In contrast, throttling and shaping rate limiters manage requests by slowing them down, delaying them, or lowering their priority. The token bucket algorithm works by maintaining a “bucket” for each target which gets topped up on a clock with a number of tokens equal to reaching the limit in matter. Each request consumes a token from the bucket in order to be admitted. When the bucket runs out of tokens, the request is denied until the bucket is refilled. The service admission approach means that engines that want to perform a security test towards a target first need to get admission from the global rate limiter, while the proxy approach would work as a more transparent “middleware” for the request between the engine and the target.
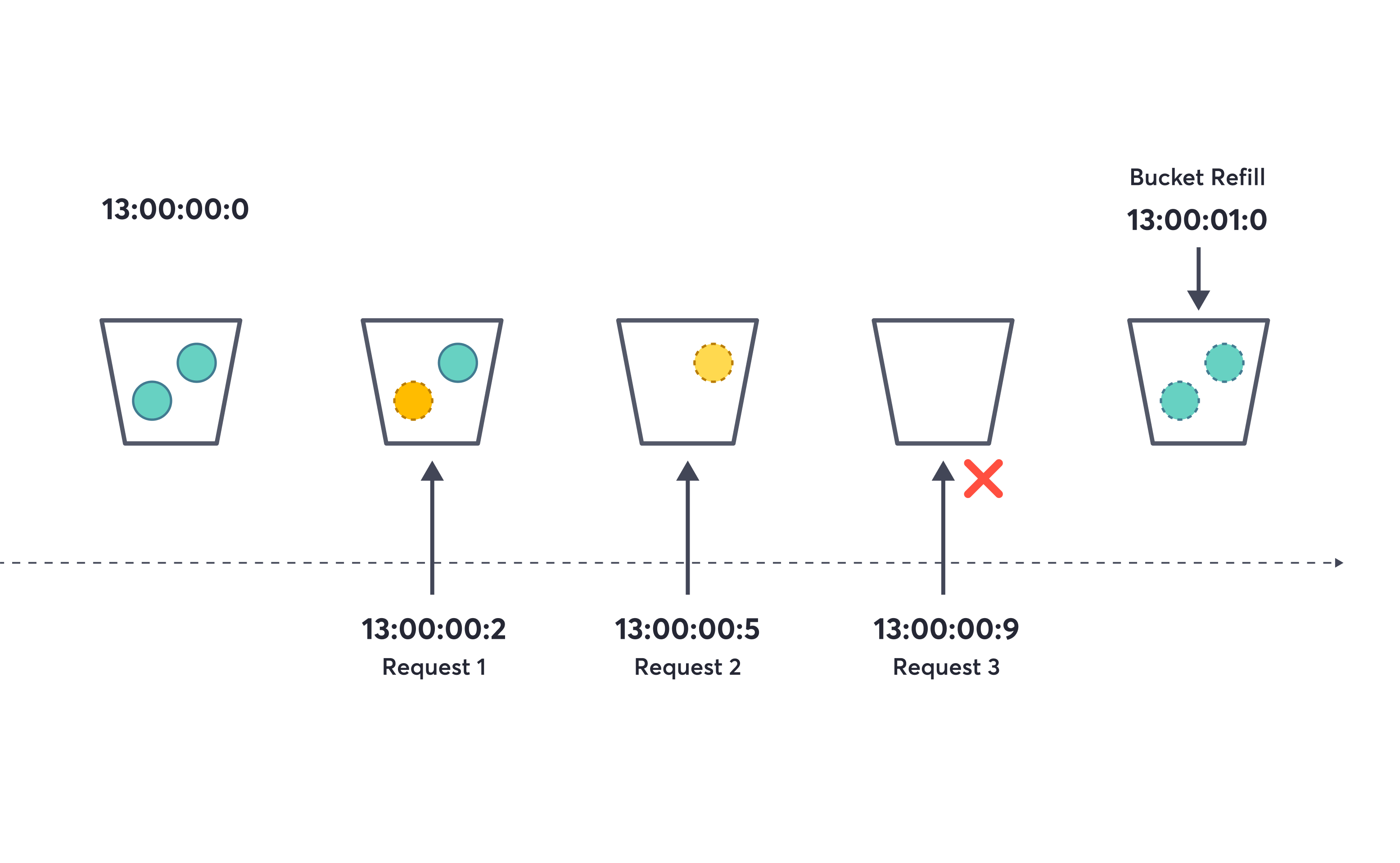
Token bucket algorithm
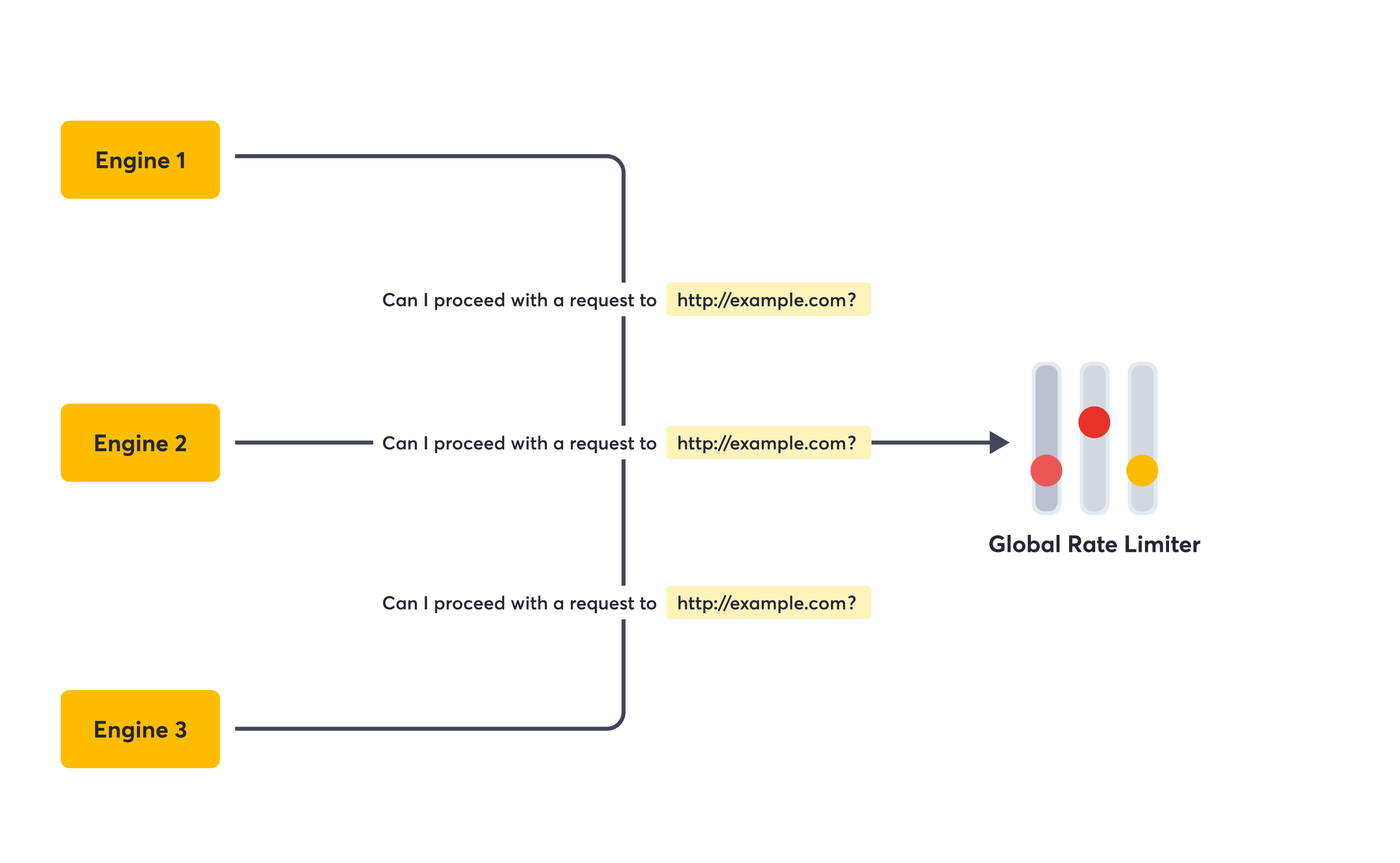
The global rate limiter as an admission service
The technical choices
With the algorithm and topology defined, it was time to explore the technologies that could best meet our needs. The global rate limiter needs to handle a high throughput of requests with a significant level of concurrency, all while operating with very low latency and being scalable.
We further expanded on these requirements and determined that the solution should run in memory and involve as few internal operations as possible. E.g., leveraging atomic operations and simple locks with expiration policies. In the hot concurrency spot, we opted for a single-threaded approach that would run sequentially, avoiding the overhead of concurrency controls.
After discussing our options, we concluded that the best solution was to run the global rate limiter service on long-living ECS tasks backed by a Redis sharded cluster. Since we use AWS, we found it convenient to utilize ElastiCache for creating our Redis sharded cluster.
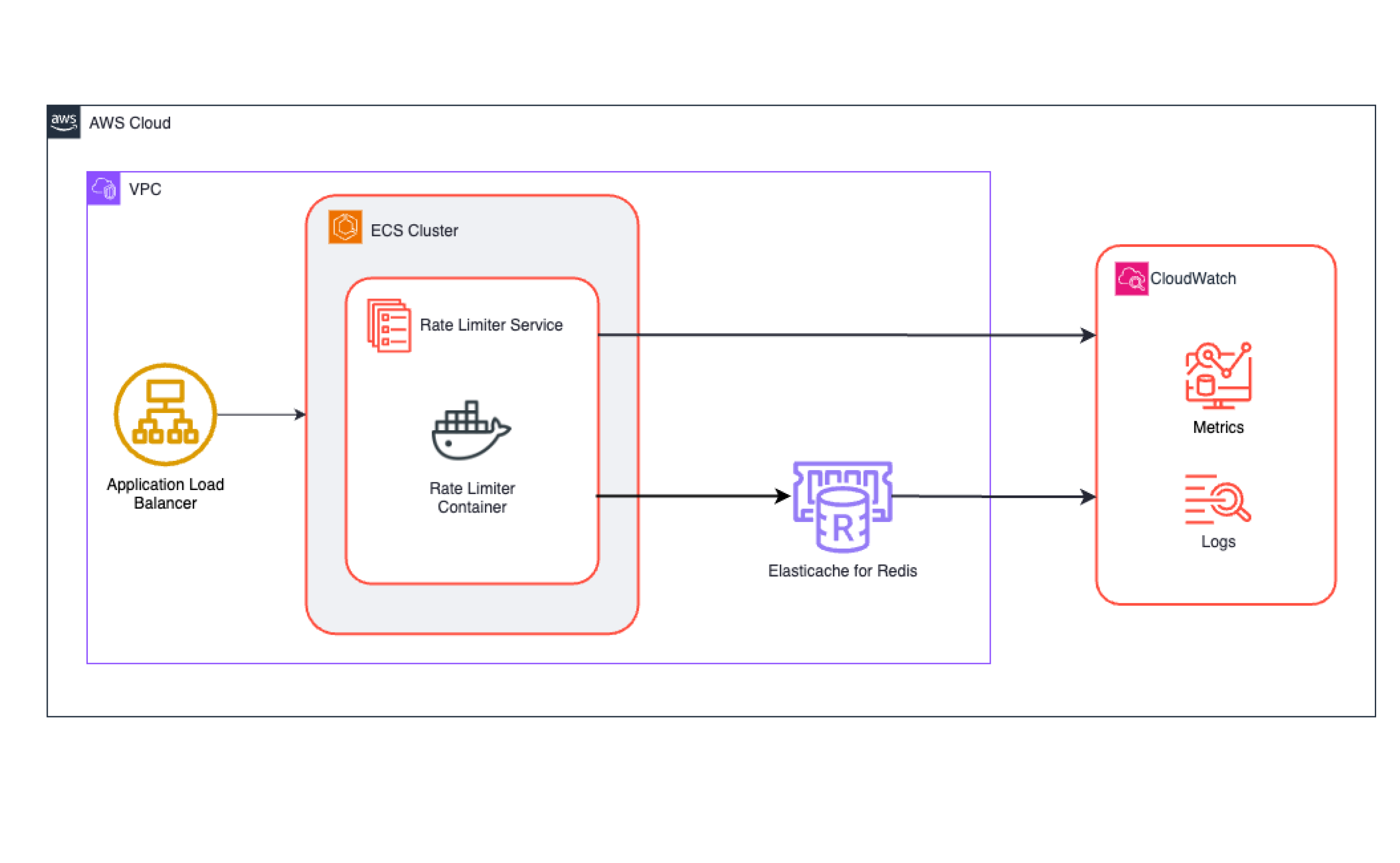
High-level design of our global rate limiter
Show me the code!
The global rate limiter service is rather straightforward, providing a simple API for requesting admission to a target. The more interesting aspect lies in the implementation of the token bucket algorithm between the service and Redis.
We aimed to leverage atomic operations and simple locks with expiration policies, while also running tasks sequentially in the areas of high concurrency. This sequential execution was straightforward with Redis, as it operates in a single-threaded manner. Our focus was to place the concurrency challenges onto it. The simple locks with expiration policies were convenient with Redis, as one of the areas it excels in. At this point, we just had to concentrate on designing the algorithm with as few service-Redis interactions and as atomically as possible. After some iterations, we settled on a solution that runs a Lua script on the Redis server. Redis guarantees the script’s atomic execution, which fits the bill perfectly.
Let’s have a look at the code, with detailed explanations following:
local bucket = KEYS[1] local tokens = ARGV[1] local tokensKey = bucket..":tokens" local lockKey = bucket..":lock" local tokensKeyExpirationSec = 1 local lockKeyExpirationSec = 1 local admitted = 1 local notAdmitted = 0 local refilled = 1 local notRefilled = 0 if redis.call("decr", tokensKey) >= 0 then return { admitted, notRefilled } end if redis.call("set", lockKey, "", "nx", "ex", lockKeyExpirationSec) then redis.call("set", tokensKey, tokens - 1, "ex", tokensKeyExpirationSec) return { admitted, refilled } end return { notAdmitted, notRefilled }
The script takes a few parameters: the bucket name and its limit value for the tokens. As for the time window, we are only working with 1-second time windows. Then, going into checking for admission, the first thing we do is to try and decrement a token from the bucket. If there are available tokens, we admit the request. Otherwise, we check if it’s time for refilling the bucket. To do that, we use Redis’s capability of setting the lock key if it does not exist and provide the 1-second time window as expiration time. If we manage to set the lock key, it means we have entered a new time window and can refill the bucket, which we do while returning the approval to proceed. If we didn’t have enough tokens, and we could not refill the bucket yet, we deny the request. The tokens key also has an expiration time so that we don’t have to do extra cleanups after requests towards a target haven’t happened in a while.
How is it performing?
We have been satisfied with the performance since its inception. On average, it handles 20K requests per second, with occasional peaks of up to 40K requests per second. The p99 latency is normally lower than 4 milliseconds, and the error rate nears 0%.
One interesting challenge related to observability is determining how many requests are performed towards a single target. For those familiar with time series databases, using targets as labels would not work, leading to an explosion in cardinality. An alternative could be to rely on logs and build log-based metrics, but if one looks at the volume that we are dealing with, they can imagine it would be extremely costly in financial terms.
To tackle this challenge, we had to think creatively. After some ideation, we decided to log at the moment the buckets get refilled. While this method doesn’t provide the exact number of requests made to a target, it does indicate the maximum number of requests that could be sent to a target at various points in time. This is the essential information for us, as it allows us to monitor and ensure we do not exceed the specified limits.
More engines and tests, safer customers
Keeping our customers secure is about achieving the perfect technical balance to ensure a safe way of running security tests on their attack surfaces without causing unexpected load issues to their servers and potentially affecting their business. The implementation of our global rate limiter allowed us to safely increase the number of engines and security tests in our inventory, running more security testing without breaking their systems.
From an engineering perspective, implementing a global rate limiter presents an interesting technical challenge, and we found a solution that works well for us. If any changes arise, thanks to the extensive ideation throughout the whole process, we are ready to adapt to ensure we provide a safe and reliable experience to our customers. That said, go hack yourself!
Interested in learning more about Detectify? Start a 2-week free trial or talk to our experts.
If you are a Detectify customer already, don’t miss the What’s New page for the latest product updates, improvements, and new security tests.






