
Grok 4 is a huge leap from Grok 3, but how good is it compared to other models in the market, such as Gemini 2.5 Pro? We now have answers, thanks to new independent benchmarks.
LMArena.ai, which is an open platform for crowdsourced AI benchmarking, has published the results of Grok 4.
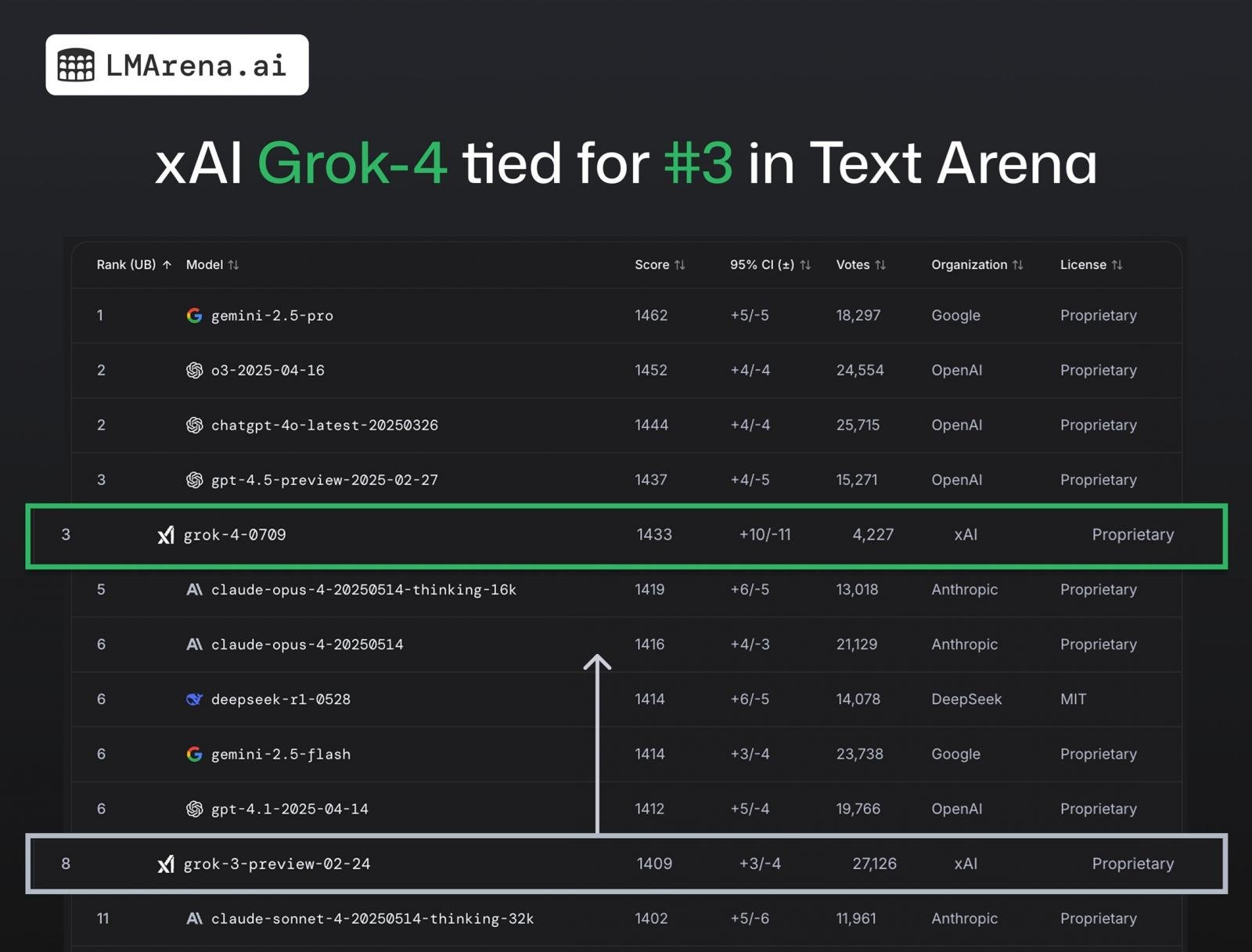
We’re talking about Grok 4 API (grok-4-0709), which received about 4k+ community votes and ranks #3 overall in Text Arena. This is a huge leap from Grok 3, which ranked 8th.
According to LMArena’s tests, Grok 4 scores Top-3 across all categories (#1 in Math, #2 in Coding, #3 in Hard Prompts).
Grok 4 was tested with real-world prompts across domains like coding, math, as well as creative writing, and it performed really well:
- Math: #1
- Coding: #2
- Creative Writing: #2
- Instruction Following: #2
- Hard Prompts: #3
However, it is worth noting that the tested model is Grok 4, not Grok 4 Heavy.
While both are reasoning models, Grok 4 Heavy is significantly better.
The numbers could be different with Grok 4 Heavy, which uses multiple agents to think and compare results, but the Grok 4 Heavy model is not yet available on the API platform.
Gemini 2.5 Pro and Claude still remain the best models for coding, but that might change when xAI ships Grok 4 Code in August.
Grok 4 Code is optimised for coding, and we’re also expecting a CLI, similar to Gemini CLI and Claude Code.

While cloud attacks may be growing more sophisticated, attackers still succeed with surprisingly simple techniques.
Drawing from Wiz’s detections across thousands of organizations, this report reveals 8 key techniques used by cloud-fluent threat actors.





