
bbrf, here integrating with subfinder from projectdiscovery.ioLike anyone involved in bug bounty hunting, I have encountered a number of challenges in organizing my reconnaissance data over the years. In this article, I want to introduce the solution I have designed to address some of those headaches, hoping that it may prove useful to you in some way.
Get started
If you’ve stumbled on this article looking to get started with BBRF immediately, head over to the GitHub repo right away! If you’re interested to learn more about what it is (and what it ain’t), feel free to continue reading below.
What’s the problem?
When it comes to reconnaissance, or “recon”, in bug bounty hunting, it is clear that there is a lot of tooling available. Whereas five years ago, subdomain bruteforcing with fierce was all the recon I could muster, the community today has access to an abundance of very good tools that either specialize in very specific tasks (e.g. massdns), try to be amazing all-rounders (e.g. ffuf) or successfully combine a lot of submodules into one big framework (e.g. amass).
My biggest struggle when working with this growing variety of tools was always: being organized. In particular, managing the output of different tools and combining them to enrich each other was cumbersome enough that I kept on using tools on an ad-hoc basis. In other words, I would use tools for their specific purpose, interpret and use the output manually, and move on to the next one.
To overcome this problem in an attempt to be more structured, I started implementing bbrf, which in the first place had to be a command-line tool allowing me to easily list all domains and IPs belonging to a project, and to store domains and IPs for later use. In particular, I was longing to be able to run commands like: bbrf domains and bbrf ips to list my data, and sublist3r.py | bbrf domain add - to store my results.
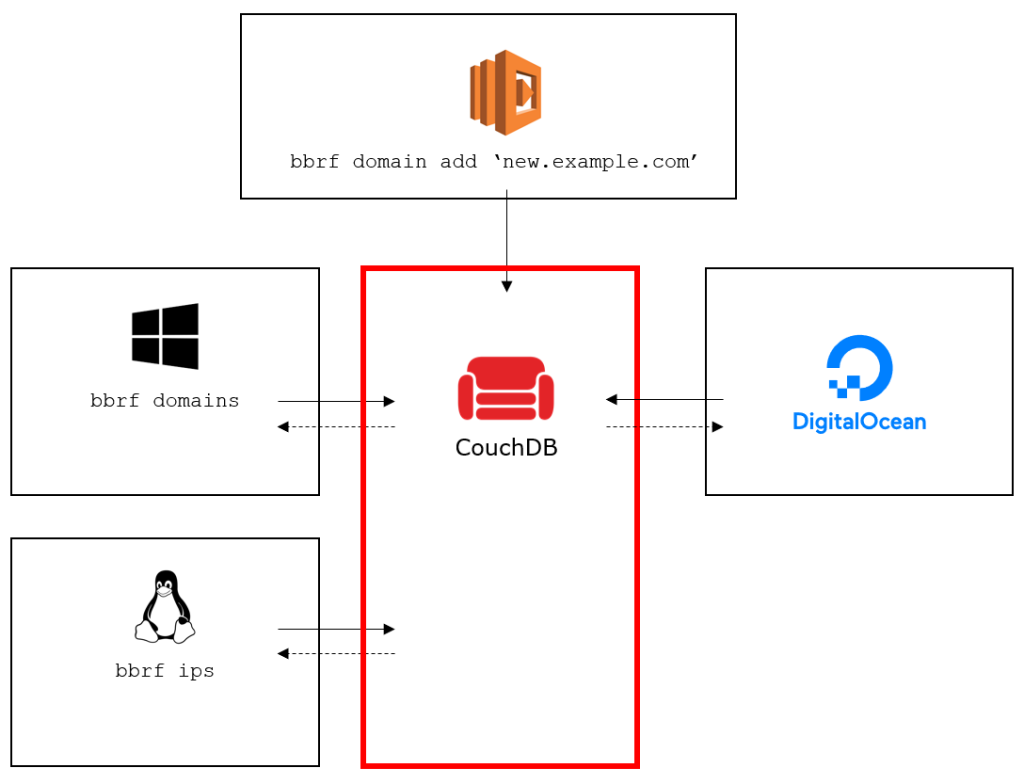
Architecture
To achieve the desired functionality, BBRF was designed as two separate components: the BBRF server, in the form of a central document store, and the BBRF client in the form of a Python script.
Document store
The document store, or BBRF server, is a central document-oriented database running on CouchDB. CouchDB comes with a standard HTTP-based API, which allows interacting with the database by means of HTTP requests. Data is stored in JSON documents which has the advantage of not requiring any predefined data structure.
At the time of publishing, the following document types are supported by default:
- programs, including a list of inscope and outscope domains and a disabled flag;
- domains, belonging to a program and containing a list of IPs they resolve to;
- ips, belonging to a program and containing a list of corresponding domains;
Client
The BBRF client, on the other hand, can be thought of as a Python wrapper around the HTTP calls to the JSON database. It was built with simplicity in mind, according to the Linux adagio to “do one thing and do it well”, with its primary purpose to output and digest domains and IP addresses, so as to work well together with other tools by piping input and output to and from the client.
# find all domains that contain "dev" bbrf domains | grep 'dev'
# pipe all domains from subfinder into bbrf bbrf program scope --wildcard --top | subfinder | bbrf domain add -
Features
Programs & Scopes
BBRF stores your recon data in programs, in line with how bug bounty platforms typically work. Create a new program with bbrf new and define both the inscope and outscope domains to get started:
$~ bbrf new test $~ bbrf inscope add '*.example.com' 'www.example.com' $~ bbrf outscope add 'blog.example.com'
Now every added domain will be checked against the known domains and the defined scope before being ingested in the central database:
$~ bbrf domain add 'test.example.com' 'blog.example.com' 'demo.example.com' 'test.example.com' 'www.example.org' $~ bbrf domains demo.example.com test.example.com # note that the outscoped domains have been omitted
Collaboration & Distribution
Because of the central database, you can install a client on any number of machines and configure them to point to the same BBRF server. This allows you to run daily cron jobs on your VPS in the cloud, and readily access their output from your local workstation. Or to collaborate with other bug bounty hunters, and always work with the same recon data, independent on where it came from or who discovered it.
Extensibility
Since all information is written to JSON documents, the data format can be easily modified. Anything that can be represented in JSON can be stored in a new JSON document, or appended as an attribute to existing programs, domains or IPs. This would allow, for example, to also store a list of identified URLs, open ports, file hashes, full HTTP responses, etc. These changes would not require any modification on the server side, except for additional views if the data needs to be indexed and queried. In the Python client, a number of simple changes and additions would allow interacting with that data from the command line.
All other features of CouchDB can be leveraged on your BBRF server. For example, think of user-based access control, data replication across multiple servers, the Fauxton interface to interact with your data through an admin panel, or the ability to write a custom dashboard to visualize your recon data.
AWS Lambda (aka Cloud Magic)
BBRF comes with a Serverless configuration file that makes it easy to deploy a BBRF instance to AWS Lambda out of the box. This allows you to interact with the central repository from your micro services running in the cloud:
curl https://abc.execute-api.us-east-1.amazonaws.com/dev/bbrf -d 'task=domains -p vzm'
I have used this to save the results from a number of integrated agents deployed to their own lambdas to aggregate data from tools such as crt.sh, dnsgrep and sublister that regularly run recon scripts in the AWS cloud.
The Power of JSON
Because of its architecture, BBRF stores all data as raw JSON. BBRF supports querying any JSON document by its identifier, which allows you to quickly inspect the stored information from your command line:
$~ bbrf show example | jq
{
"_id": "example",
"_rev": "11-e7a49b214e37e5cc890a3620fde8a0c5",
"outscope": [
"blog.example.com"
],
"passive_only": false,
"type": "program",
"inscope": [
"*.example.com",
"www.example.com"
],
"disabled": false
}
$~ bbrf show www.example.com | jq
{
"_id": "www.example.com",
"_rev": "1-1c63d262fd46ace7f8eeb0fdd5370d07",
"ips": [],
"program": "example",
"type": "domain"
}What it ain’t
BBRF does not intend to be another all-in-one recon automation tool. Instead, it aims to provide a simple interface to integrate with the existing tools you already know and love, and to allow sharing your results across devices.
Neither was it designed to ingest every type of data, and transform it into a uniform dataset. By default, bbrf will only process domains and IPs that are piped to it in newline-separated form and in plaintext format.
At the time of publishing, bbrf only supports domains and IPs, which means there are a number of known limitations:
- No support for URLs;
- No support for ports and services;
- No support for IPv6;
Feedback
I really hope this project can help you overcome some of the issues you are facing, in the same way it has helped me over the time that I have been using it. And I really look forward to seeing more people adopt this in their day-to-day workflows.
However, since I have never held a developer role (and my coding consequently is pretty rubbish), I expect there may be some feedback about bugs you will inevitably encounter, or features that you believe are missing. In that case, please turn to the GitHub issues page or create a new Pull Request and hopefully we can sort things out!






