
Monash University is piloting graph database technology to track relationships between researchers, publications and equipment with the aim of improving return on research investment.
Monash University’s Clayton campus
iStockPhoto
The Melbourne-based university has developed a centralised platform on Amazon Web Services to help users more easily find information across its research ecosystem, using multi-modal generative AI.
Known as the Research and Publications Pattern Analysis (RAPPA), the platform combines graph database capabilities from Amazon Neptune with generative AI services from Amazon Bedrock.
Speaking at the AWS Public Sector Symposium in Canberra, Mahyar Nasabi, Monash program manager for systems and analytics, said the platform aims to provide a “missing link” between the university’s investments and publications, which he described as a kind of “currency” for universities.
“You can find all the research, income and also the publications, but they’re not linked together,” he said.
“These are sitting in siloed datasets, which creates an unclear return on investment.”
Nasabi said the fragmentation also affects students who are searching for specific information about researchers, published papers, or scientific services.
“As a research student, you want to quickly access and find specific [information],” he said.
“That is currently not really possible because you have to go to fragmented, siloed data.”
Highlighting the scale of the challenge, Nasabi noted that Monash currently has 112,000 researchers across its eight campuses, contributing to 54,000 peer-reviewed publications and in receipt of $7.6 billion in research awards.
“RAPPA essentially unifies the research ecosystem,” he said. “It brings researchers to research capabilities, research income to research output.
“Everything is in a single platform and available to query.”
Three core user personas
Before developing RAPPA, Monash University first established three key personas who would benefit from the system, each accessing it through a natural language-enabled chatbot.
A key persona is Monash’s research performance team, which reviews published papers to determine which facilities and equipment were used in the research.
Philipp Gerbert, AWS solutions architect, said the team usually relies on cues in abstracts and acknowledgements to determine equipment used, due to the complexity and length of academic papers.
To assist, one of RAPPA’s key functions for the research performance team is to automatically generate a plain-language summary of each paper, making the content easier to understand.
It then uses a multi-modal AI model to extract text, images and charts from the paper to “infer” which equipment may have been used in the research.
The research performance team will still be required to validate equipment usage before any conclusions are finalised.
Meanwhile, students and researchers also benefit from RAPPA’s improved access and discoverability when searching for relevant publications, experts, and research services.
Monash’s senior leadership and executives, who require data and insights for decision-making and governance reporting, can also gain a clearer view of equipment usage, research output, and active industry collaboration across the university.
“RAPPA is harnessing the power of AI and embedding itself in the workflow, Nasabi said. “It empowers them to do things that they were not able to do in the past.”
AI meets graph databases
The RAPPA proof-of-concept has ingested 14,000 of the university’s publicly available research and Capability Finder, Monash University’s comprehensive equipment database.
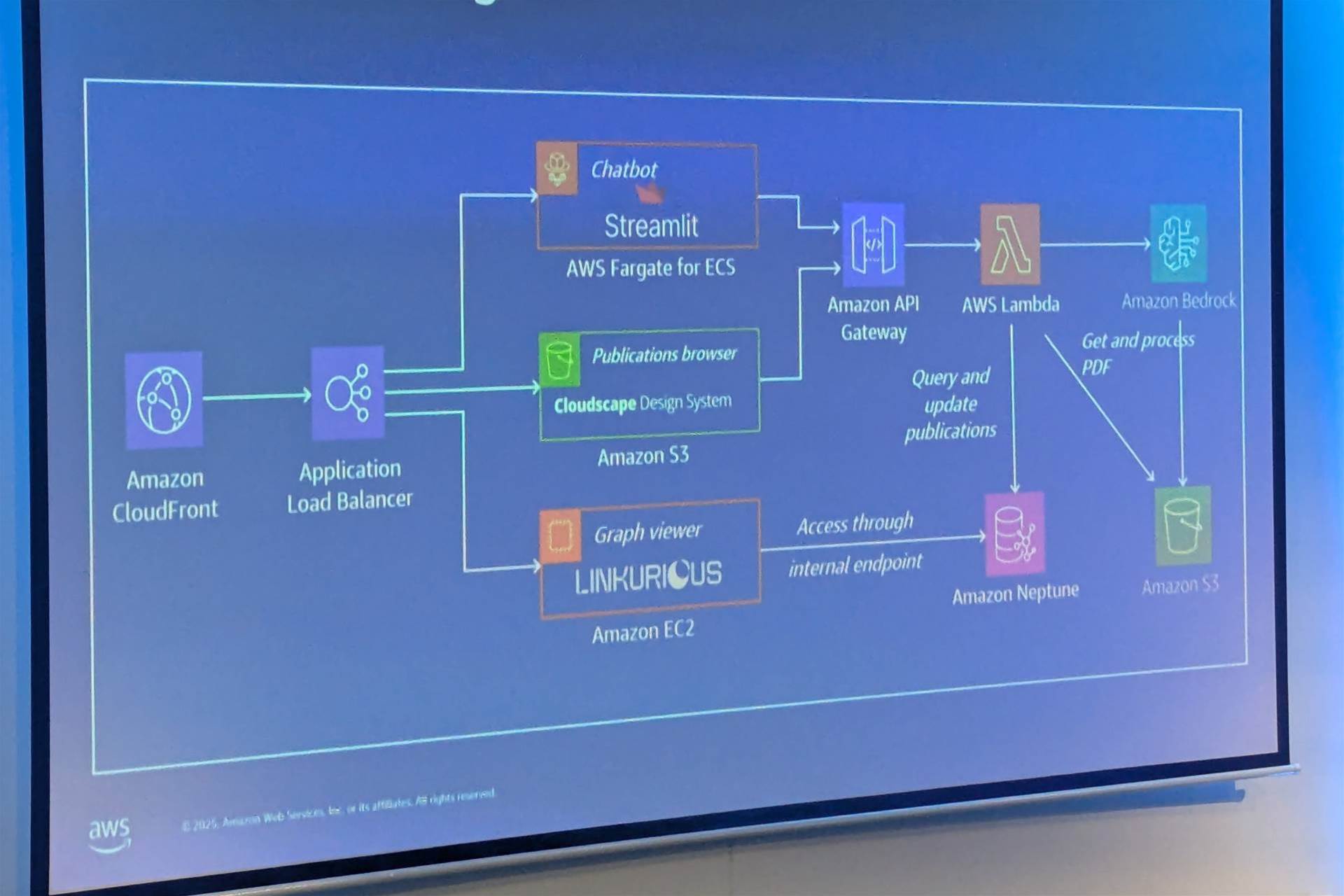
The platform’s frontend includes three main applications: a chatbot interface underpinned by Streamlit and running in a container; a custom-built publications browser designed with AWS’s Cloudscape Design System; and a graph viewer powered by the third-party tool Linkurious.
At the core of RAPPA is Amazon Neptune, a graph database that stores all relationships between entities such as researchers, equipment and facilities.
Meanwhile, Amazon Bedrock provides RAPPA’s generative AI capabilities using models from Anthropic, which analyses equipment usage to build a knowledge base.
Using AWS Lambda as a routing layer, user queries are funnelled through Amazon API Gateway, then processed by Bedrock and Neptune, generating AI-powered summaries or visualising research relationships, respectively.
All resulting relationships are stored in Neptune, while static content and files are stored in Amazon S3.
“It makes the strategic reporting much simpler,” Nasabi said.
“It was possible before, but now it is many times faster and more accurate.”
Nasabi added that Monash is open to collaborating with other universities to bring RAPPA into full production, but noted that it still requires further development before it reaches an enterprise-ready stage.
Eleanor Dickinson attended the AWS Public Sector Symposium in Canberra as a guest of AWS.




