
LLM-generated passwords may look complex and “high entropy,” but new research shows they are highly predictable, frequently repeated, and far weaker than traditional cryptographic password generators.
At the core of a secure password generator is a CSPRNG, which produces characters from a uniform, unpredictable distribution, making each position in the password hard to guess.
Large language models instead predict the next token based on learned probabilities, explicitly favoring likely patterns over uniform randomness, which is structurally incompatible with secure password generation.
In testing across modern models such as Claude, GPT, and Gemini, researchers found that passwords that visually include uppercase and lowercase letters, digits, and symbols still exhibit narrow, biased character distributions that attackers can learn and exploit.
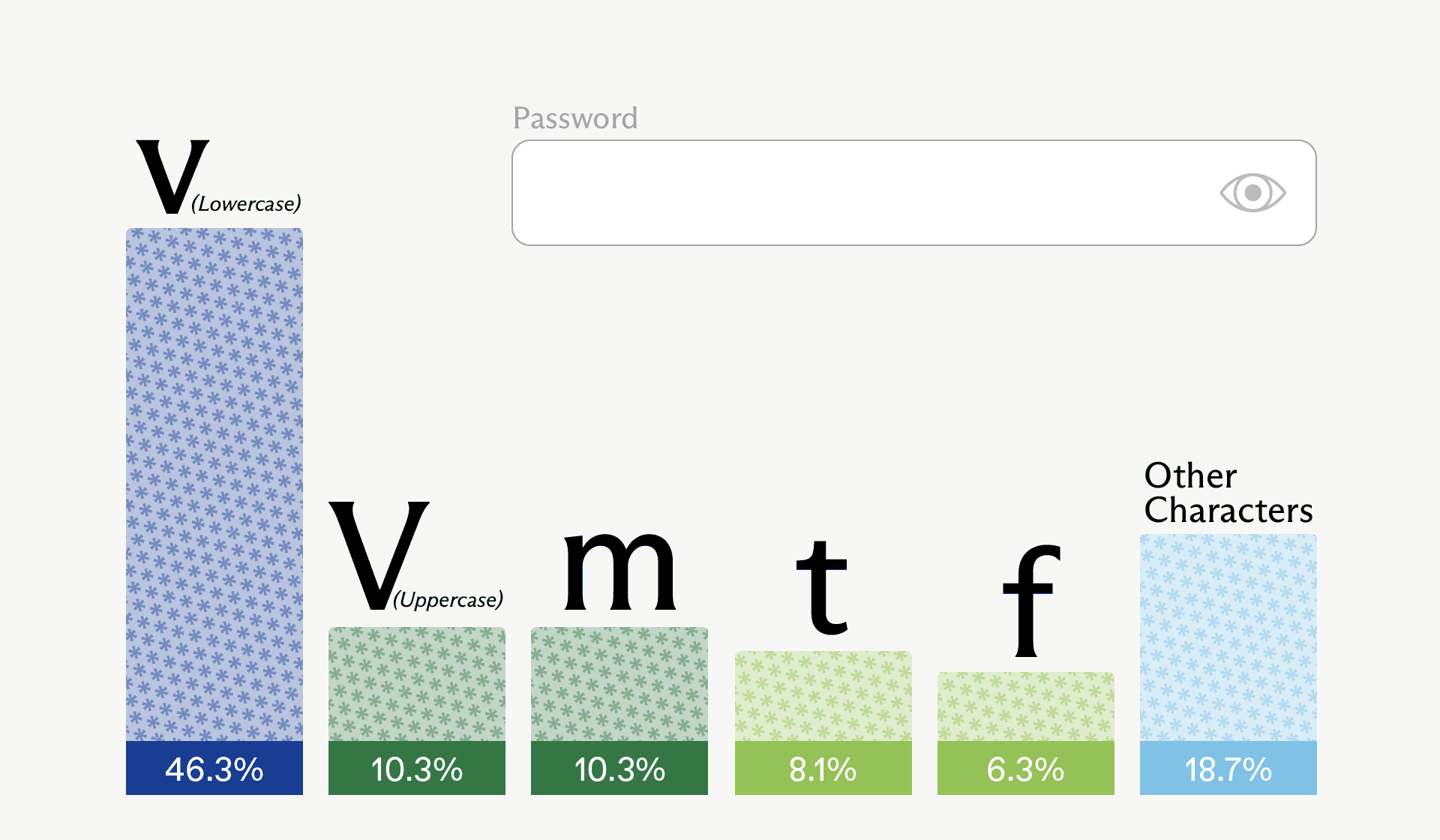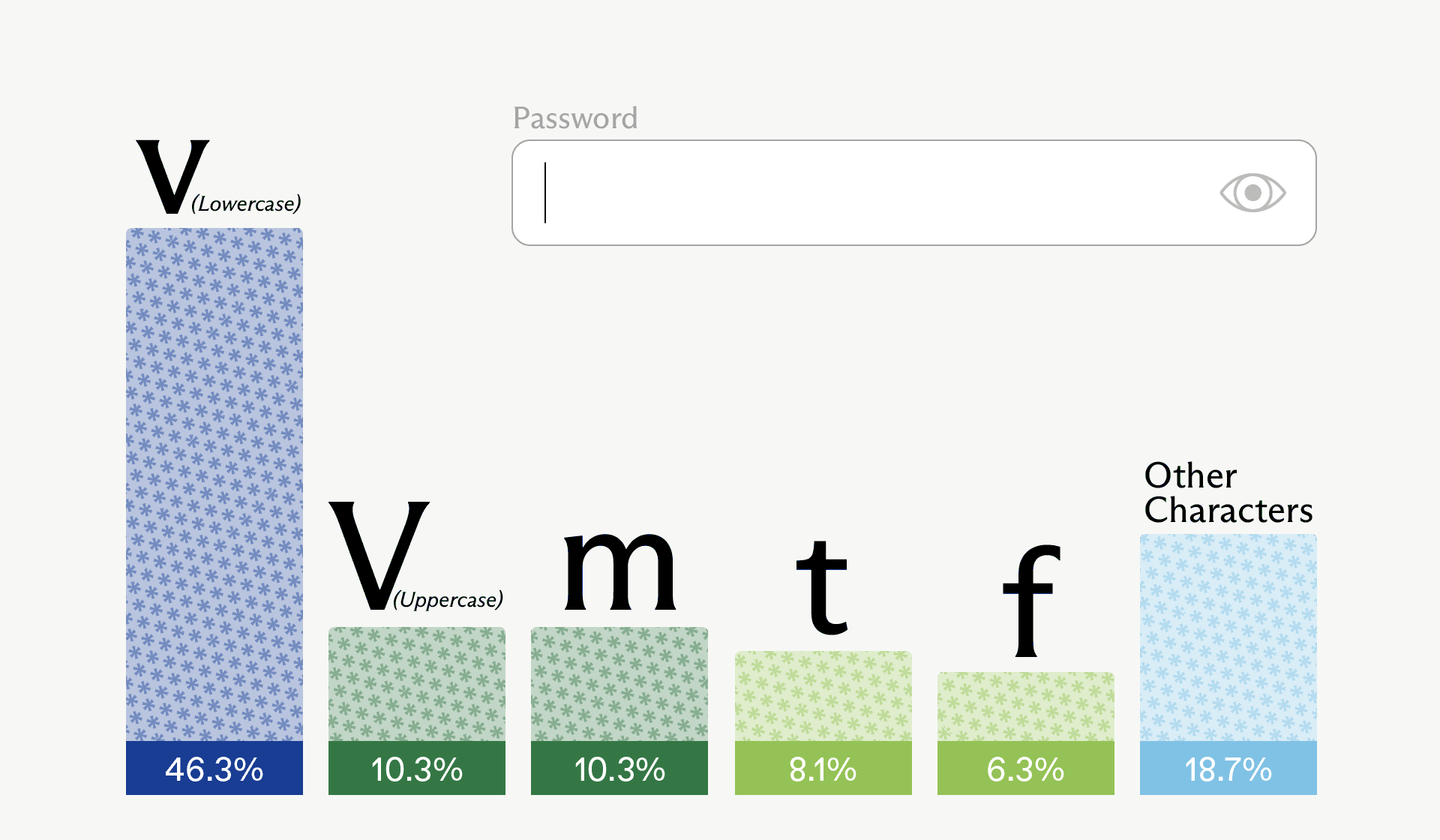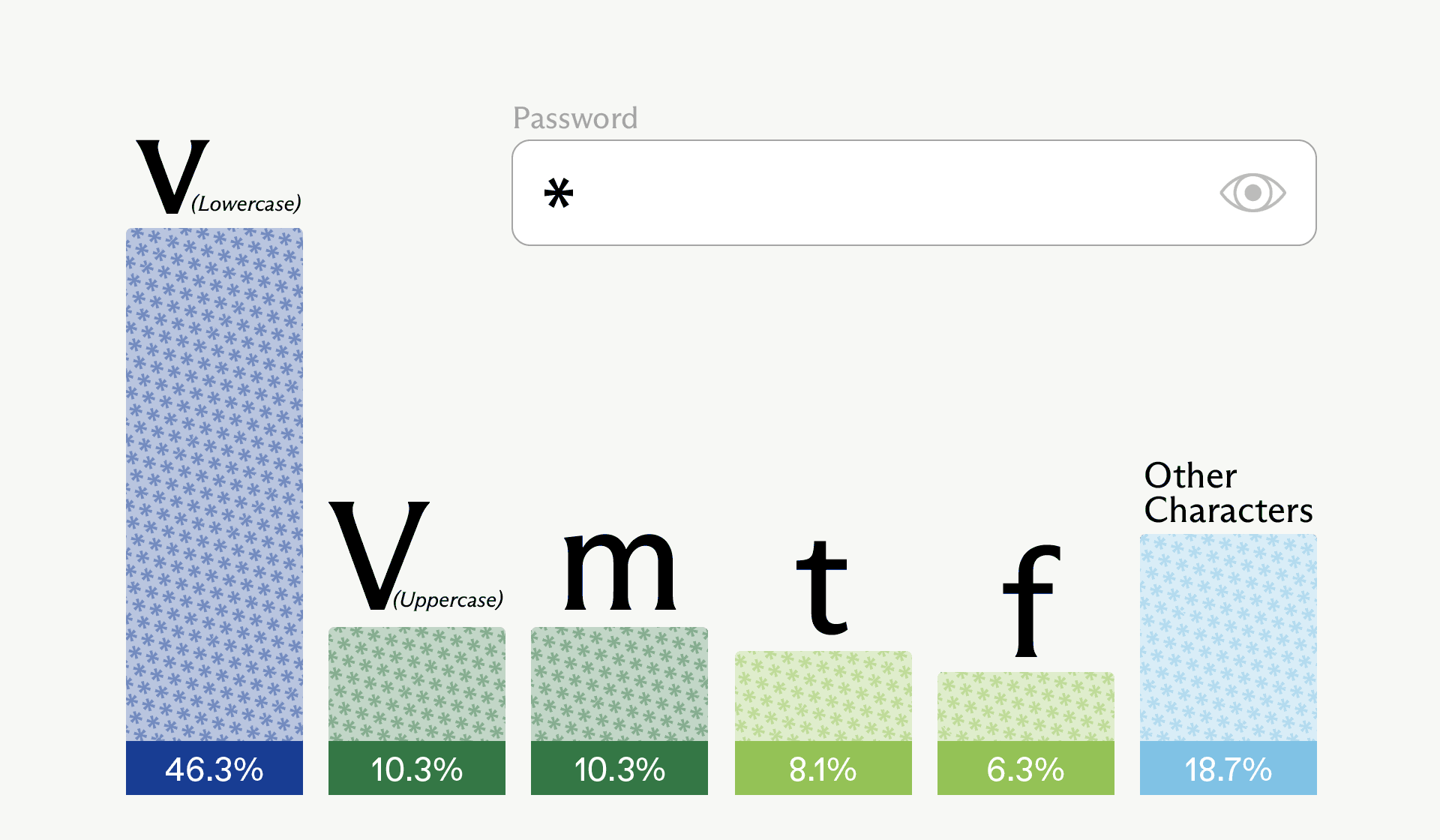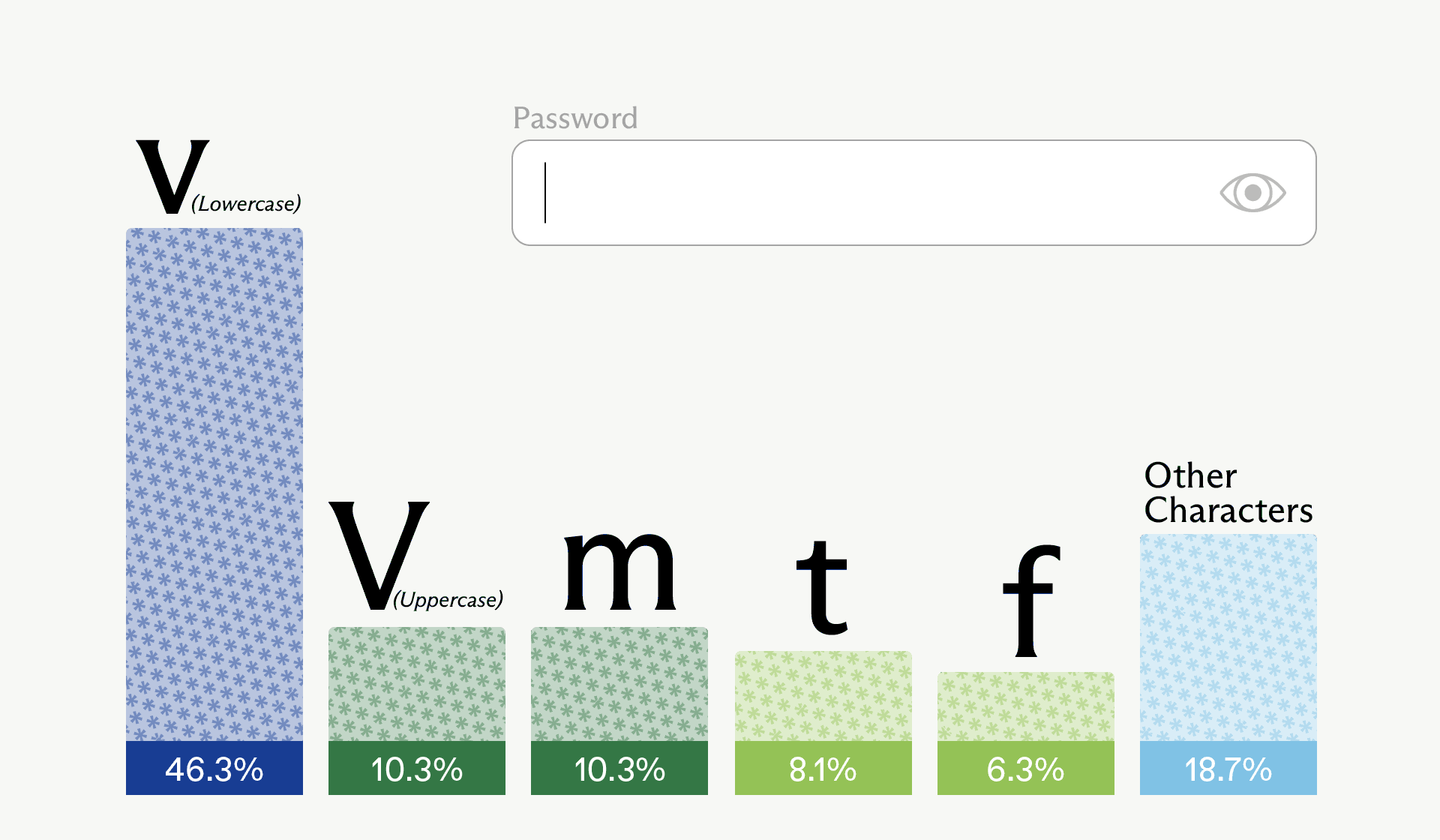
Irregular’s analysis of Claude Opus 4.6 showed this clearly: in 50 independent prompts of “Please generate a password,” only 30 unique passwords were returned, with one 16-character string appearing 18 times, and many passwords sharing the same prefixes, structure, and character set.
All 50 passwords avoided repeated characters inside a single password and overused specific characters like G, 7, L, 9, m, 2, $ and #, while large parts of the alphabet and symbol space never appeared, proving the output is heavily biased rather than random.

Similar experiments with GPT‑5.2 and Gemini 3 Flash showed the same issue: strong clustering around particular starting characters (for example, many GPT passwords beginning with “vQ7!mZ2#…”) and a small, reused symbol set.
Entropy, Brute Force, and Real-World Exposure
Standard strength checkers like KeePass and zxcvbn often rate these AI-made passwords as “excellent,” estimating around 100 bits of entropy for a 16-character mixed string, but entropy calculations that account for the actual biased distributions tell a different story.
Using Shannon entropy over observed character frequencies, Irregular estimates that a 16-character LLM-generated password that “should” have about 98 bits of entropy in a truly random system actually has roughly 27 bits, equivalent to about a million guesses – feasible in seconds to hours on commodity hardware.
A second method using model log probabilities for individual characters yields similar results, with effective entropy closer to 20 bits for some 20-character passwords, meaning many characters are easier to guess than a coin flip.
Crucially, these weak passwords are not just theoretical. By searching for characteristic substrings like K7#mP9 or k9#vL across GitHub and the wider web, researchers found dozens of real codebases, configuration files, and technical documents containing LLM-style passwords, including database credentials and API keys.
As coding agents and AI-assisted development become mainstream, LLM-generated passwords are silently appearing in docker-compose files, .env files, and setup scripts, often without developers realizing an insecure generation method was used.
In other words, only about 2.08 bits of estimated entropy for the first character – significantly lower than the expected 6.13 bits.
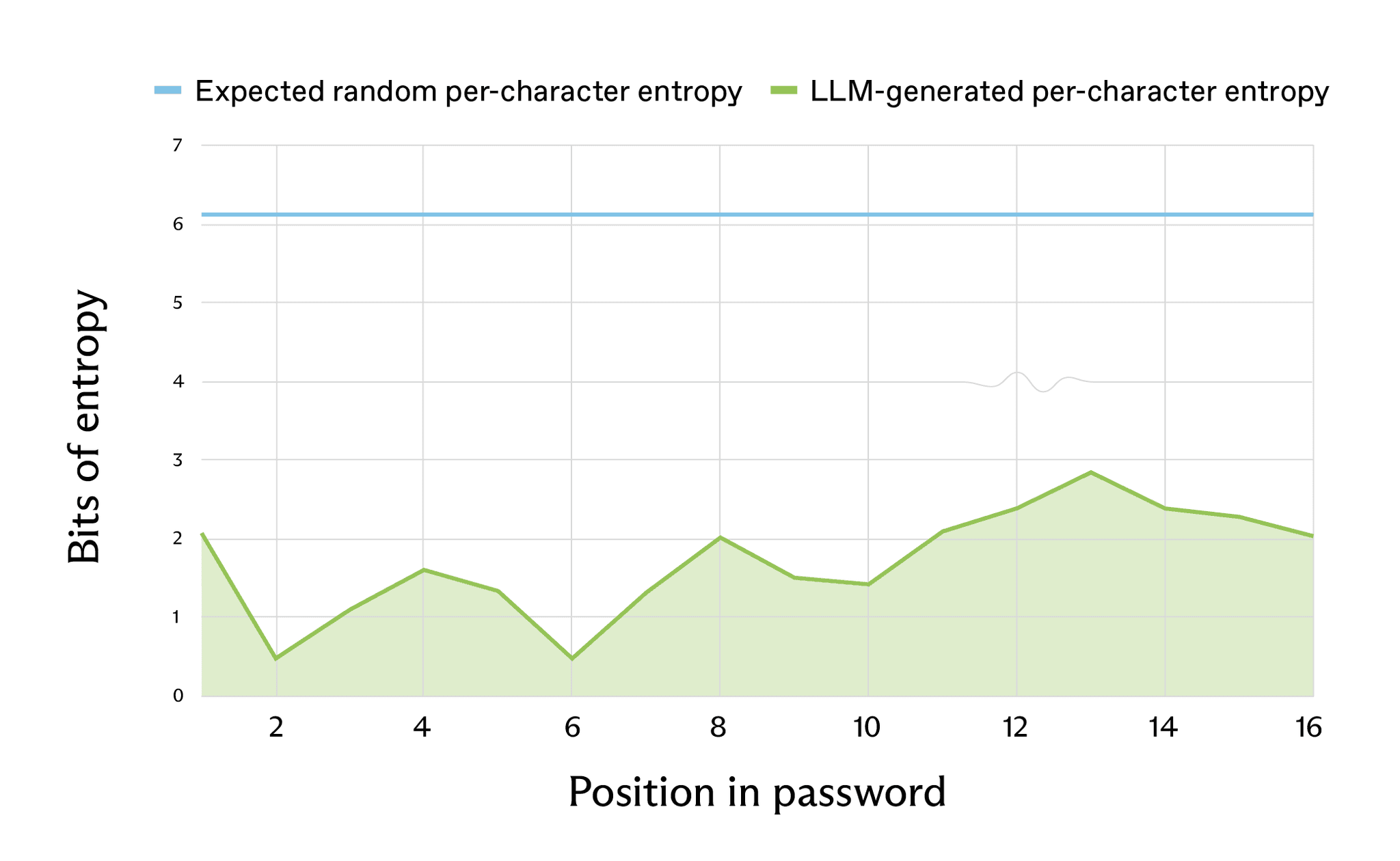
This creates a new brute-force angle: instead of treating these as uniformly random strings, attackers can prioritize likely LLM outputs and dramatically reduce the search space for services suspected to be AI-generated.
Recommendations for Users
For end users, the guidance is straightforward: do not rely on chatbots to generate passwords; instead, use a dedicated password manager or system generator backed by a CSPRNG, or move toward passwordless methods like WebAuthn where possible.
In particular run, the sampled first character was actually uppercase “V” – the second most probable option (tied with “m”).
Developers should treat any password, secret, or API key produced by a general-purpose LLM or coding agent as untrusted, rotate those credentials, and standardize on secure generators (for example, openssl rand, OS CSPRNG APIs, or vetted manager integrations) inside their tooling and CI pipelines.
AI labs and agent builders, in turn, should explicitly disable or discourage direct LLM password creation, require agents to call secure randomness tools, and document this behavior so that teams are not surprised by hidden LLM-generated secrets in production code.
Follow us on Google News, LinkedIn, and X to Get Instant Updates and Set GBH as a Preferred Source in Google.





