Deepfake detection has been built around a single question for close to a decade. Given a video or audio clip, is it real or synthetic? Commercial detectors analyze pixels, frequencies, and biometric signals to answer that question, and the best of them post strong accuracy numbers on standard benchmarks. In deployment, performance drops sharply on content from newer generators.
Researchers at the Vector Institute think this gap is structural, and closing it means rethinking what the field is trying to detect in the first place.
The interrogation analogy. Traditional detection focuses on surface-level media artifacts. An interrogation-based approach evaluates speech-act validity, interaction coherence, and manipulative intent, shifting detection from perceptual analysis to communicative structure and behaviour (Source: Research paper)
The forensic foundation is eroding
Current detectors rest on five technical assumptions. Synthetic imagery leaves visible traces where it is composited onto real backgrounds. Generative models leave characteristic fingerprints in the frequency content of an image. Video generation produces frame-to-frame inconsistencies like flicker and identity drift. Synthetic portraits fail to reproduce biological signals like natural blink patterns and the faint color variation caused by blood flow. And all of these signals survive real-world distribution through compression, re-encoding, and conferencing codecs.
Each assumption held reasonably well when GAN-based face-swaps dominated the landscape. None of them holds reliably now. End-to-end diffusion models generate entire frames with no blending step. Modern video generators handle temporal coherence. High-resolution synthesis can reproduce physiological cues. And the final assumption, that detector signals survive being passed through Zoom, Teams, or a re-encoded social media upload, has always been the least tested and the most fragile.
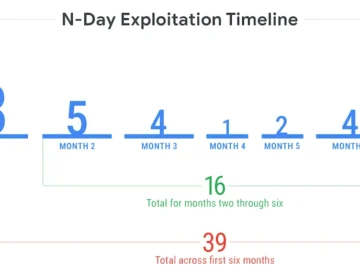
The Vector Institute team calls the result the Generalization Illusion. Benchmark scores stay high. Real-world detection performance quietly declines.
Where attacks get caught
Documented deepfake fraud cases reveal a consistent pattern. In the 2019 UK Energy voice-cloning incident, attackers cloned a CEO’s voice and instructed an executive to transfer €220,000 to a Hungarian supplier. The fraud was discovered after a follow-up call raised suspicion about the request. In the 2024 Arup case, an employee authorized $25.5 million in transfers during a deepfake video conference involving multiple synthetic colleagues. The fraud surfaced weeks later through financial reconciliation. The attempted Ferrari impersonation was stopped when the targeted executive asked a personal question only the real CEO could answer.
Automated media forensics played no role in any of these outcomes. When deepfake attacks get caught, they get caught by people noticing that something about the interaction is wrong. Unusual request channels. Broken institutional norms. Missing shared context.
A different question to ask
The research paper proposes adding a layer of analysis focused on the communication itself. It draws on frameworks from linguistics and social psychology, and the practitioner version reduces to three questions about any suspicious interaction.
Does the request fit the speaker’s authority and the normal context for this kind of decision? Does the conversation flow the way a real one would, or are there subtle violations like over-scripting, evasive answers, and abrupt topic shifts? Is the interaction stacking pressure tactics like urgency, authority claims, and appeals to social proof at unusually high density?
This communication-layer analysis runs alongside media forensics. The authors are explicit that it complements rather than replaces it, and they acknowledge the framework is largely a research agenda. The signals are still mostly drawn from work on text-based phishing and business email compromise, with extension to real-time audiovisual settings flagged as an open problem. They also note a boundary condition. An attacker who successfully mimics a normal interaction across all three communication layers leaves no signal there, and the system falls back to media forensics alone.
What works in practice
The controls that have prevented deepfake fraud in documented cases are procedural. Callback verification on known numbers. Out-of-band confirmation for high-value transfers. Challenge questions. Separation of authorization channels. These recommendations are unfashionable. They do not scale neatly into a product and they do not make for compelling demos. They work because they target what the attacks exploit, which is the interaction, and they do so on a channel the attacker cannot synthesize.
Deepfake detection as a standalone technical capability is losing ground, and is likely to keep losing ground as generative models continue to improve. Treating it as one signal among several, alongside the procedural controls that catch deception when the media looks convincing, is a more durable posture.
![]()
Download: The IT and security field guide to AI adoption